AI软件
-
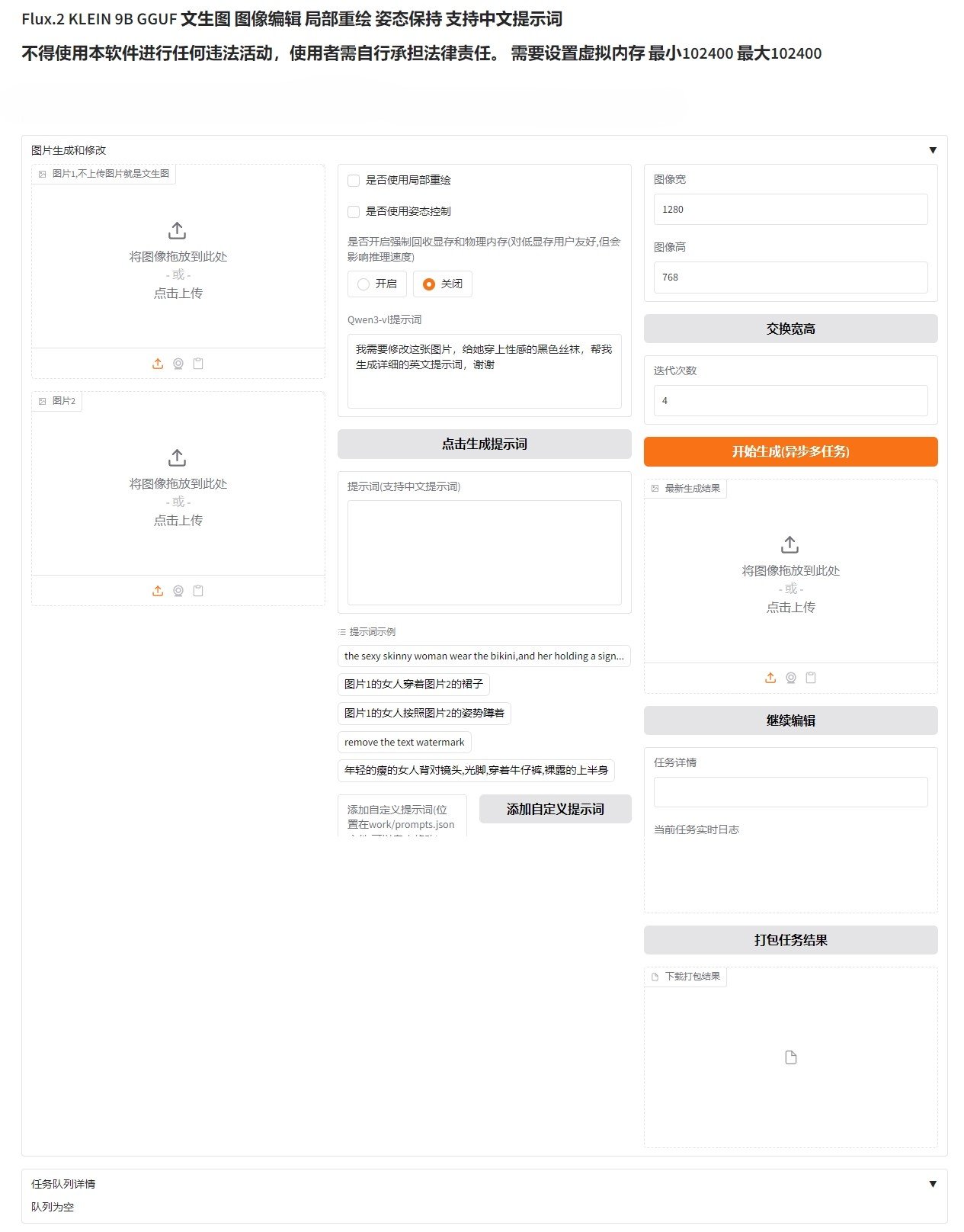
FLUX.2-Klein多模创作软件 高效低配AI图像生成工具下载
FLUX.2-Klein模型家族由人工智能研究公司 Black Forest Labs (BFL) 开发并开源。其名称中的Klein在德语中意为小,体现了其模型紧凑、高效的特点。该系列模型(特别是4B版本)采用宽松的Apac...
2026-01-31 10:23:13
-
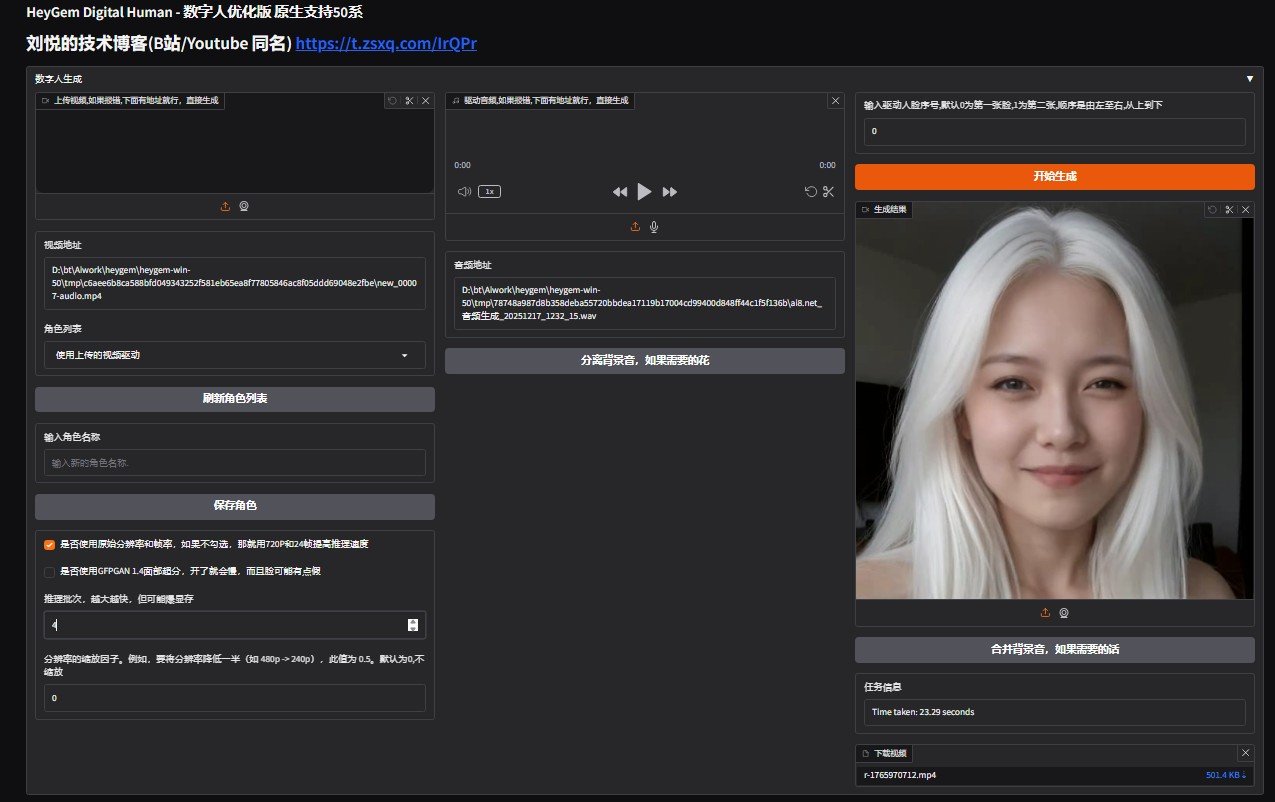
heygem视频生成整合包下载
软件介绍 heygem是帮你快速复制一个虚拟自己的软件。由南京硅基智能公司开发,而且是开源的。最大优点是不用联网、在自家电脑上就能跑,隐私有保障。 以前做数字人又贵又慢,现...
2026-01-23 20:19:15
-
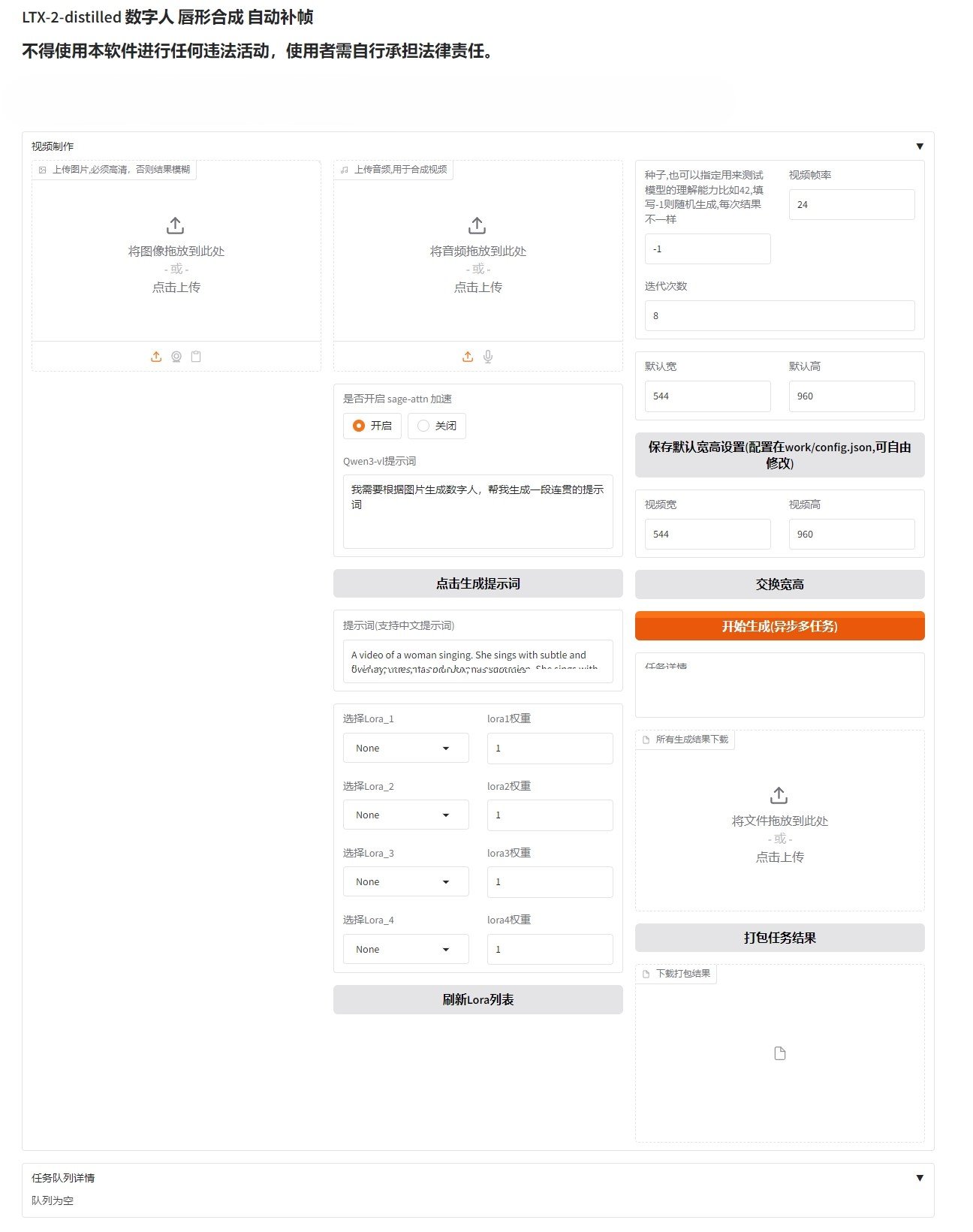
LTX-2-GGUF文图生视频工具下载 本地高清音画同步整合包
LTX-2-GGUF 是一款旨在让普通电脑也能本地运行高端 文/图生视频 的AI工具。它的核心功能是把文字描述或静态图片,变成一段带同步声音的、最长20秒的高清视频。 LTX-2-GGUF来源于Lightri...
2026-01-23 17:26:48
-
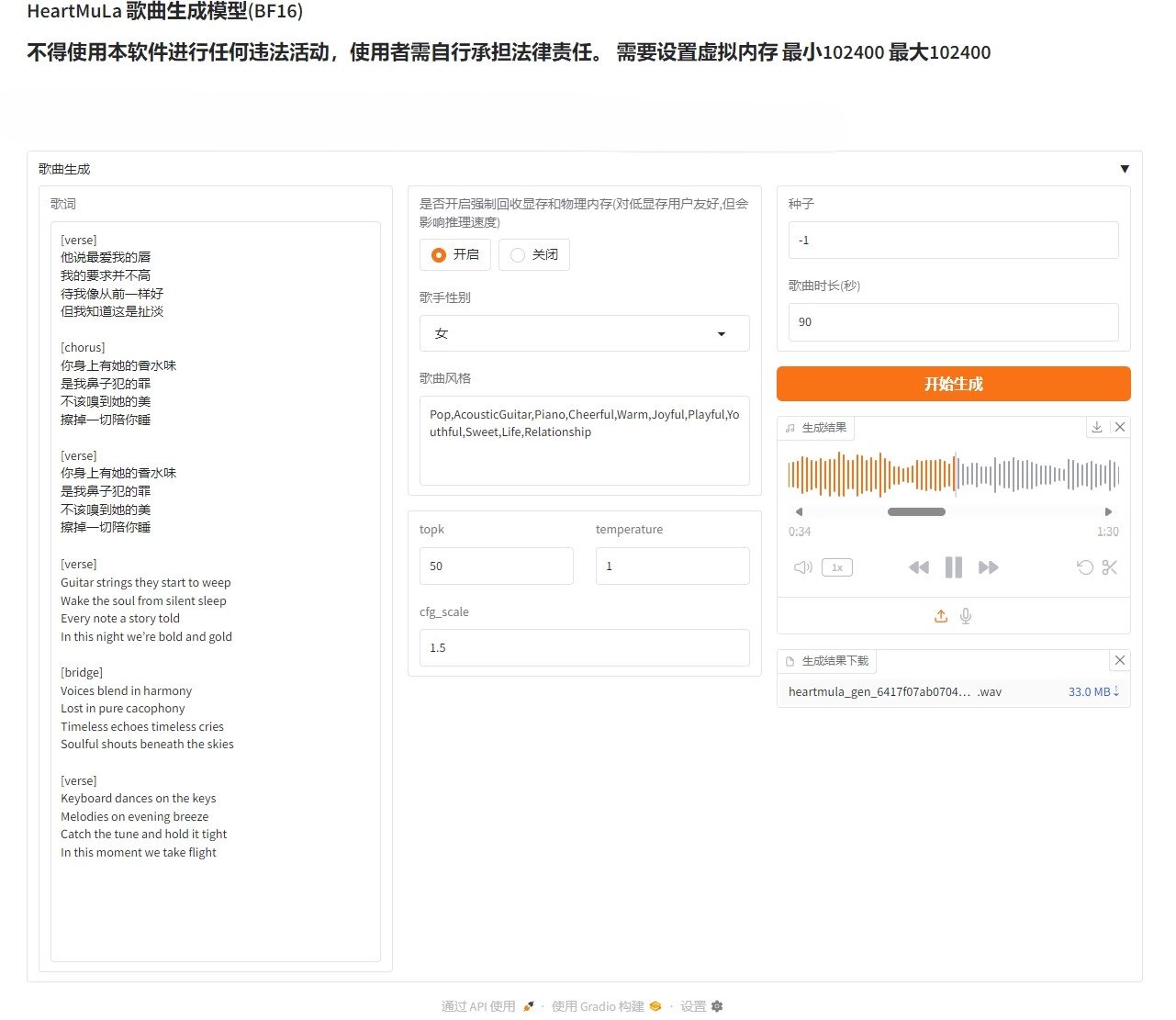
HeartMuLa开源音乐生成软件 媲美Suno的免费生成整合包下载
HeartMuLa来源于一项发表于2026年1月的尖端学术研究,由北京大学等机构的研究团队联合发布。研究团队将全部模型、代码和论文开源,旨在打造一个能媲美商业级产品(如Suno AI)的开放...
2026-01-23 17:26:17
-
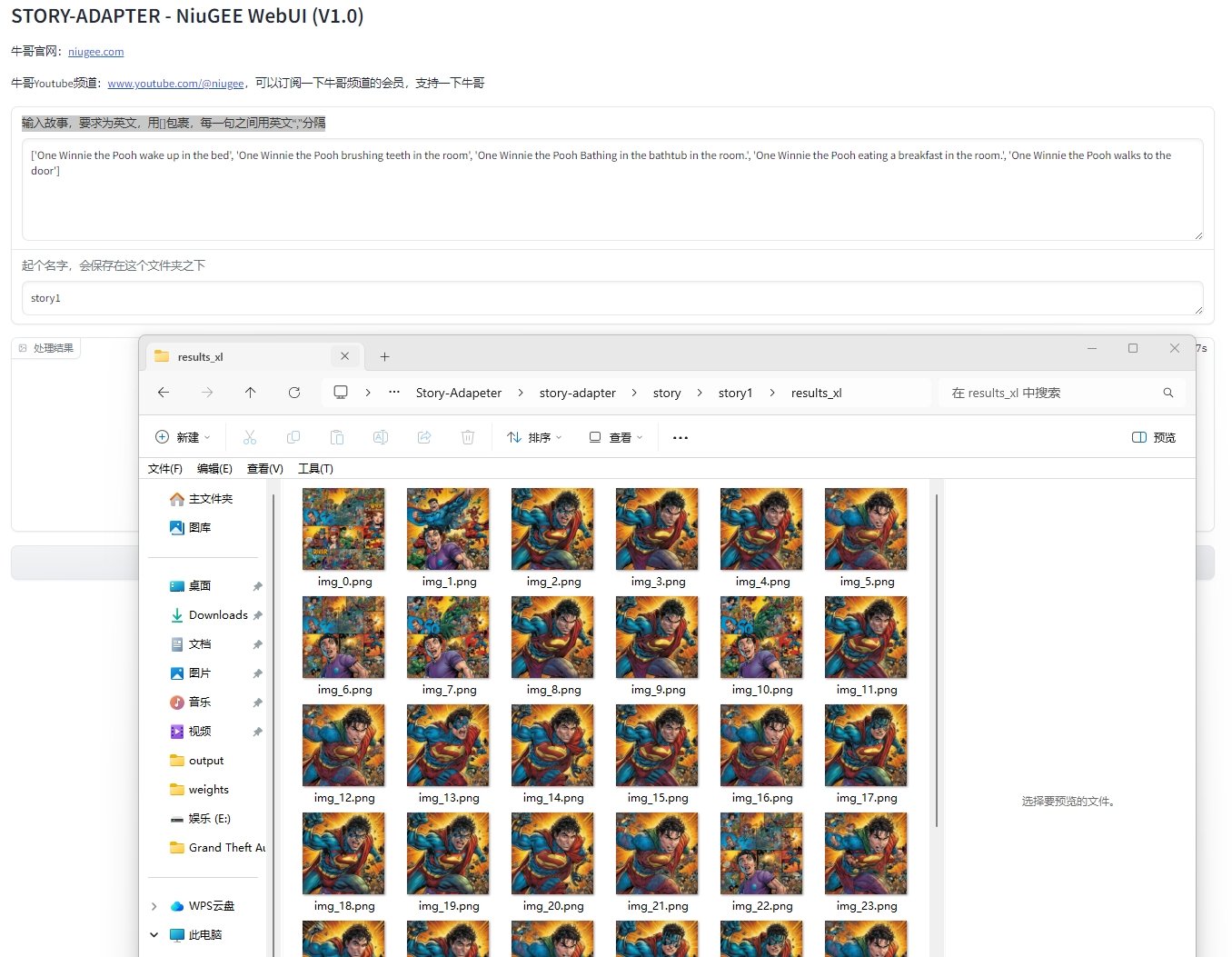
Story-Adapter故事转图 嫁接文生图长故事生成器下载
Story-Adapter是一个专门用来把长篇文字故事,自动转换成一系列连贯图片的AI工具。你可以把它想象成一个AI连环画生成器。 Story-Adapter来源于一篇发表于2024年10月的计算机视觉学术研究。...
2026-01-23 17:25:02
-
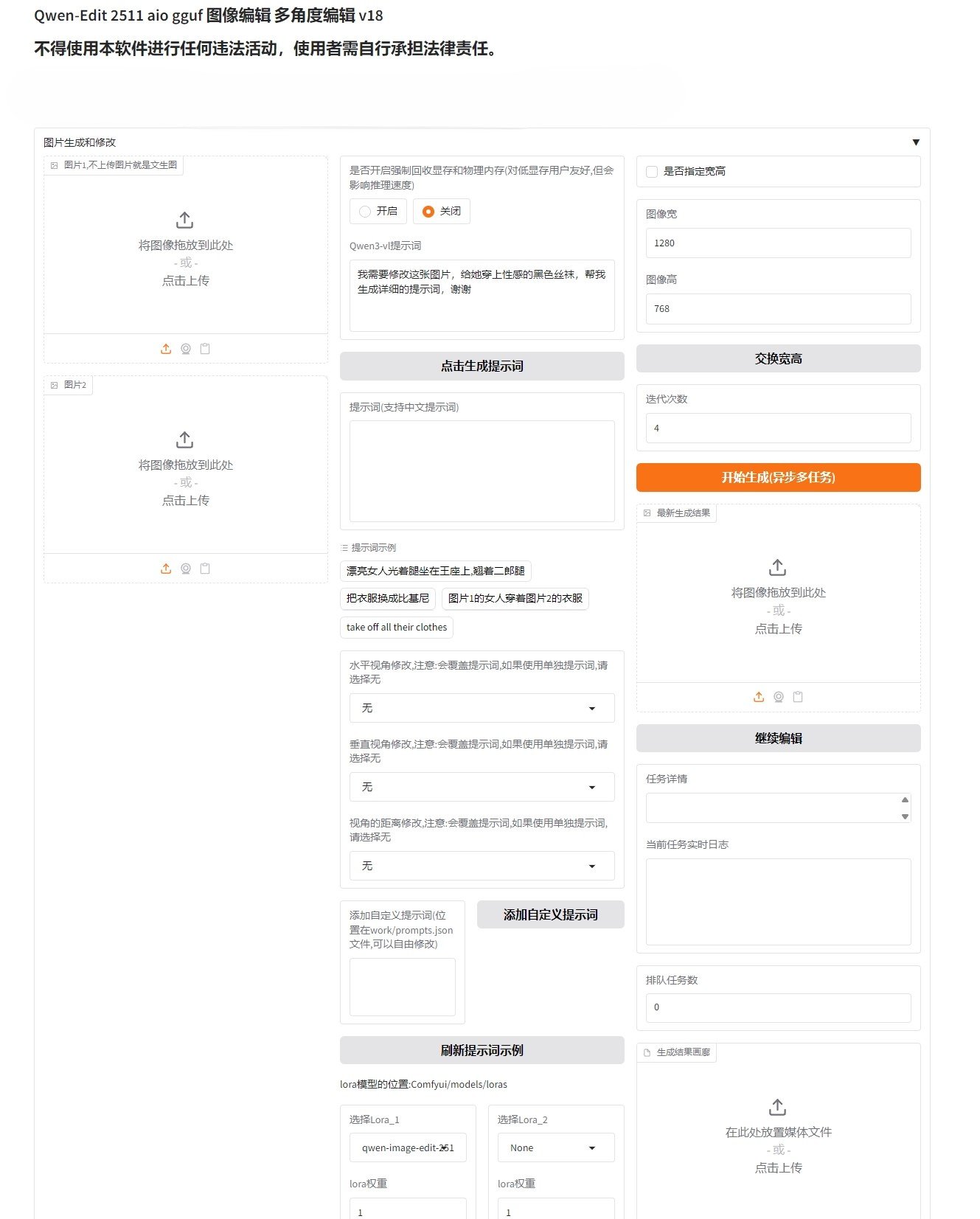
Qwen-Image-Edit-2511 人物一致精准修图工具整合包下载
Qwen-Image-Edit-2511是阿里巴巴通义千问团队在2025年12月25日正式开源的最新图像编辑AI模型。它是此前Qwen-Image-Edit-2509版本的增强版, 旨在解决图像编辑后人物或物体发生轻微漂移的问题,...
2026-01-23 17:09:46
-
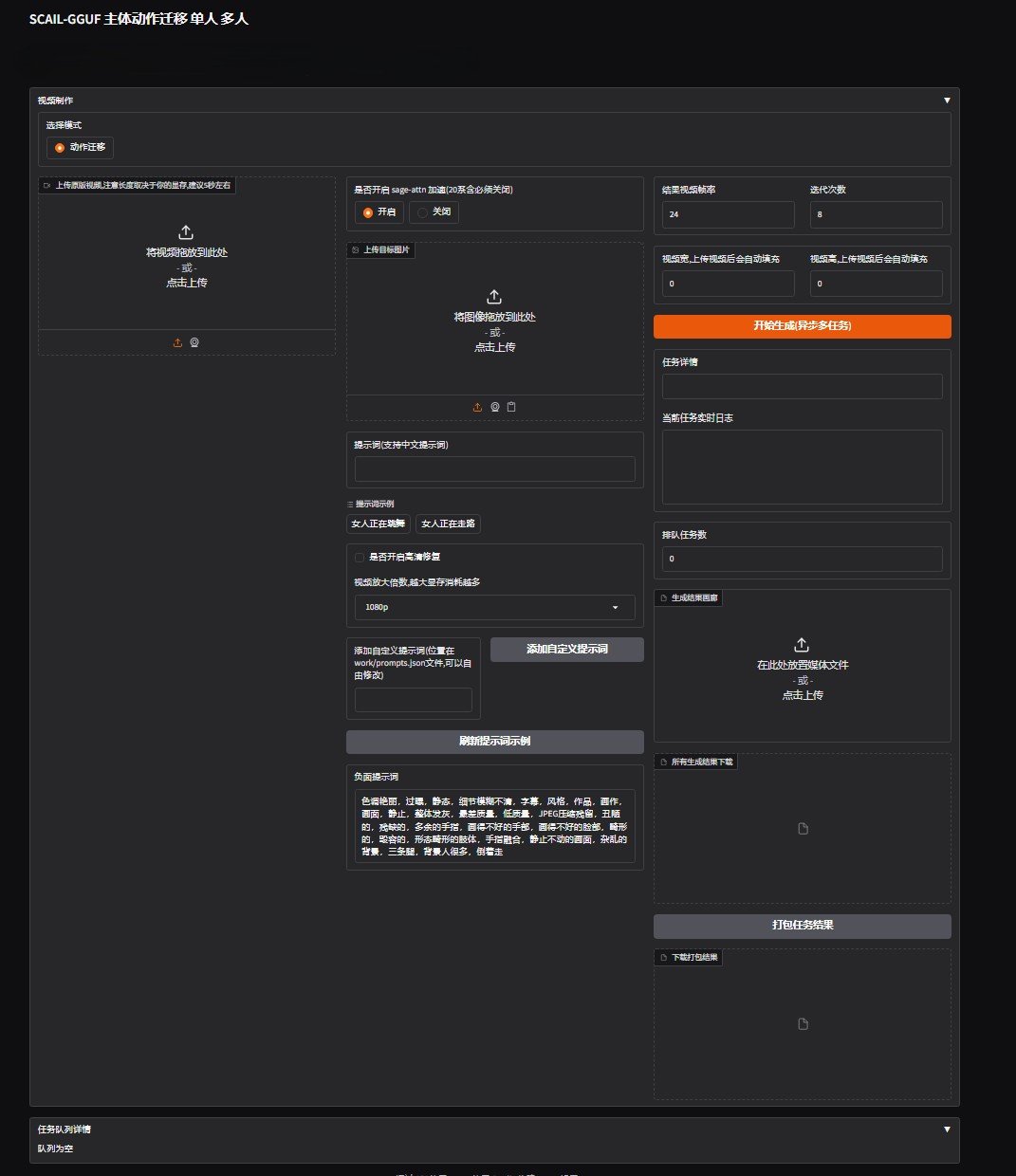
SCAIL-GGUF动作迁移整合包下载 本地离线高清修复工具
软件简介 SCAIL-GGUF模型的内核由斯坦福大学法律与语言人工智能中心(SCAIL) 研发并开源。主要核心功能是使用图片转化视频得动作迁移。 主要功能作用 先上传一段需要得动作舞蹈之类...
2026-01-19 18:35:17
-
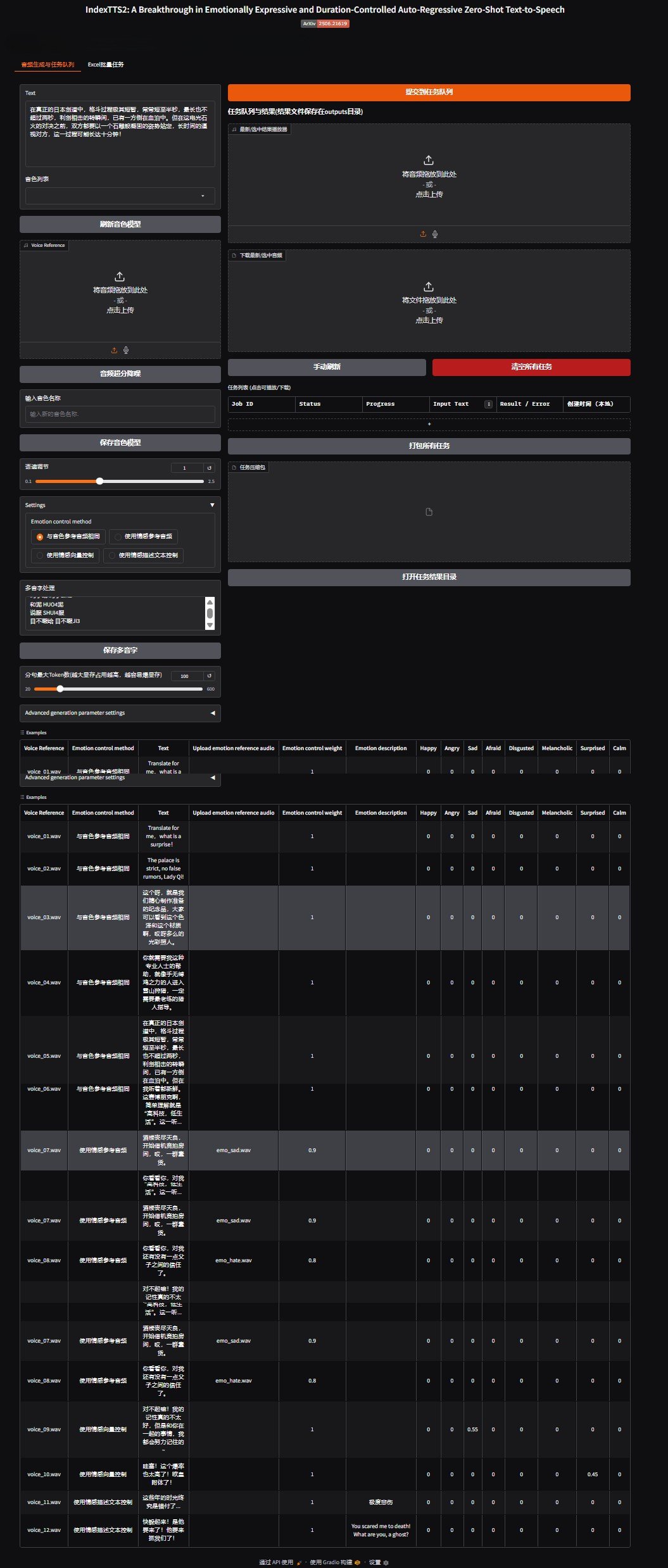
indextts2声音克隆配音软件下载 多语言情感控制工具
IndexTTS2是由平台Bilibili(B站)旗下的Index团队自主研发并开源的新一代文本转语音(TTS)模型。 该模型旨在解决语音合成中的情感表达与时长控制难题,自发布后因其卓越的性能和开放...
2026-01-19 18:34:43
-
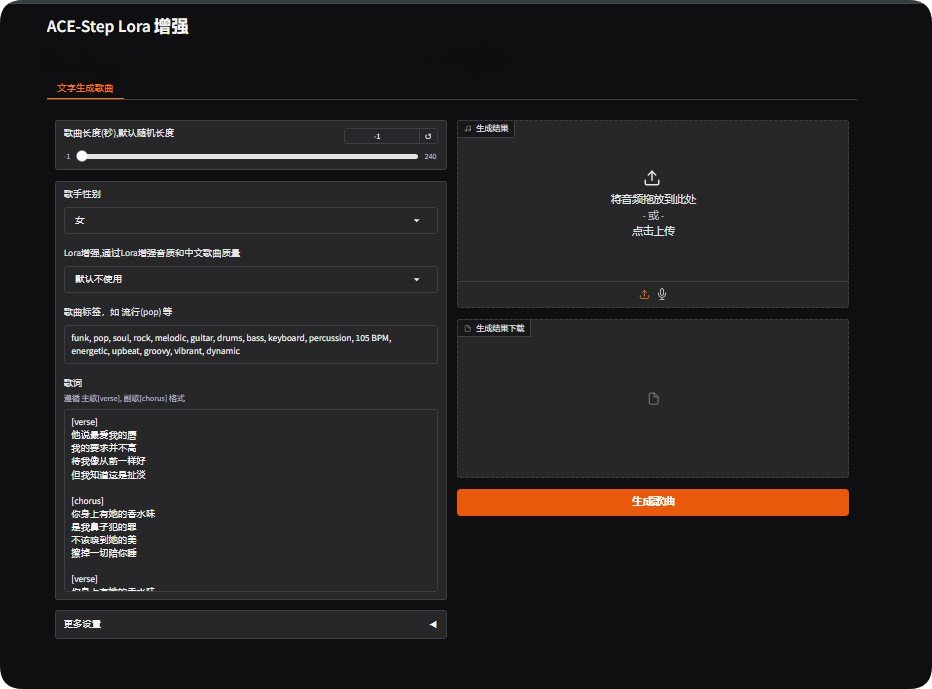
ACE-Step音乐创作工具下载 多风格多语言ai唱歌整合包
ACE-Step(中文名音跃)是由人工智能公司阶跃星辰和数字音乐平台ACE Studio在2025年5月7日联合发布的一款开源音乐生成大模型。 它参数量为35亿,是一个旨在降低音乐创作门槛、提供专业...
2026-01-19 18:34:19
-
DMOSpeech高效语音合成整合包下载 零样本声音克隆工具
DMOSpeech是由哥伦比亚大学与NewsBreak公司合作开发的突破性AI语音合成系统。 这项研究旨在解决语音合成中节奏控制不准确的核心难题。 主要功能 结合其技术目标,它的主要功能和潜在...
2026-01-19 18:33:02