AI音频工具
GPTSovits
- 2024-12-28
- 豆豆
- AI吧
GPT-SoVITS是一款语音合成模型,结合了深度学习和声学技术,能够实现高质量的语音生成。支持参考音频进行语音合成,即便不训练模型也能快速生成相似度较高的声音,通过数据调整,也能够进一步提供其相似度,情感。
具有以下特点:
零样本文本到语音(TTS):哪怕只有5秒钟的声音样本,也能帮你转换文本到语音。
少样本TTS:如果你能提供1分钟的声音样本给它,它就能更好地学习,让克隆出来的声音更加真实、更加像原声。
跨语言能力:能将合成文本的英语、日语和中文文本都转换成所需克隆的声音。
混合语言处理:合成文本如有多国语音,可同时处理生成。
应用场景:
短视频创作中的生动配音、专业解说,有声书领域的精彩制作,为亲友留存独一无二声音印记的复刻服务,以及宣传片高大上的配音制作等。
配置要求:
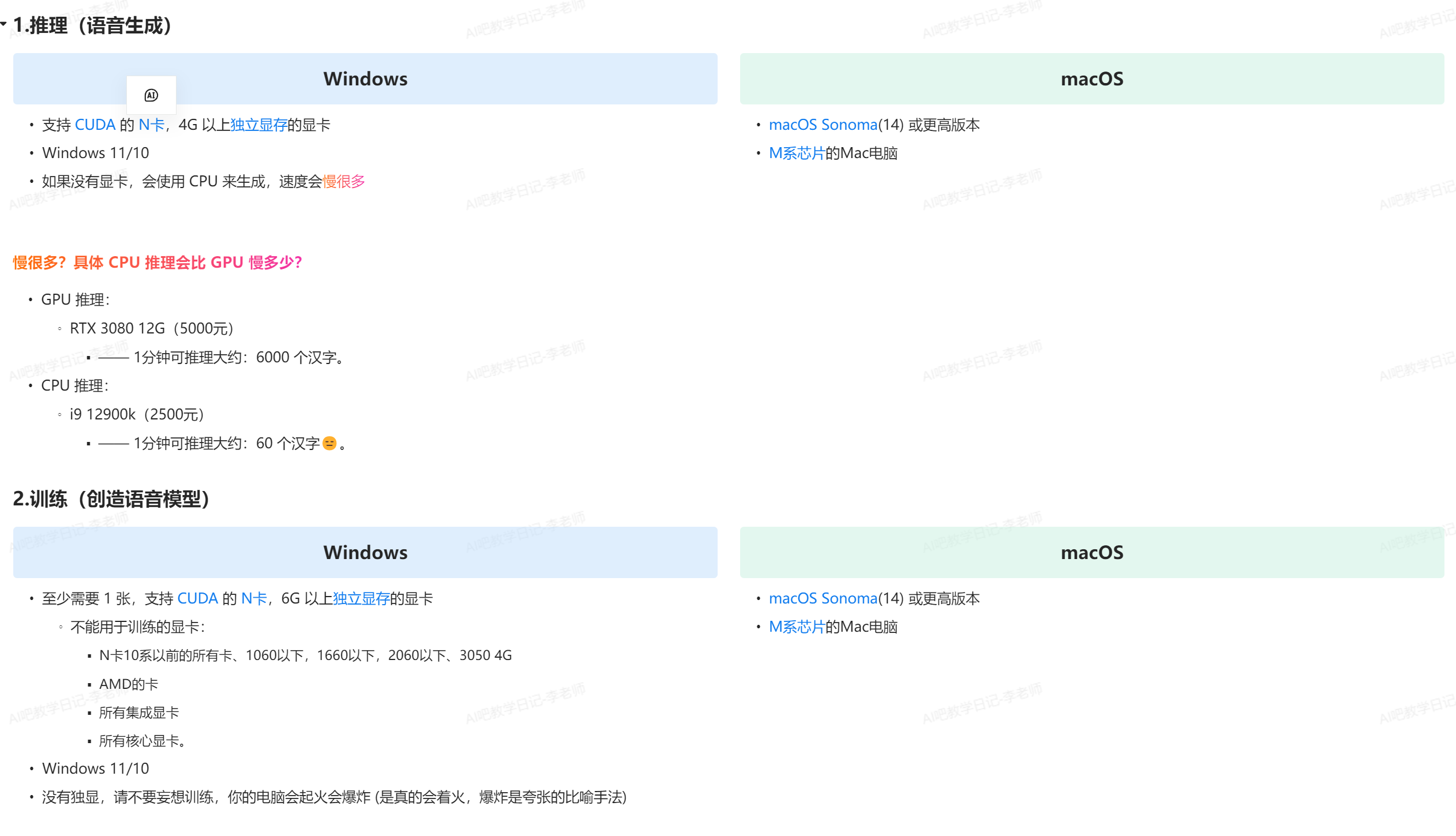
具有以下特点:
零样本文本到语音(TTS):哪怕只有5秒钟的声音样本,也能帮你转换文本到语音。
少样本TTS:如果你能提供1分钟的声音样本给它,它就能更好地学习,让克隆出来的声音更加真实、更加像原声。
跨语言能力:能将合成文本的英语、日语和中文文本都转换成所需克隆的声音。
混合语言处理:合成文本如有多国语音,可同时处理生成。
应用场景:
短视频创作中的生动配音、专业解说,有声书领域的精彩制作,为亲友留存独一无二声音印记的复刻服务,以及宣传片高大上的配音制作等。
配置要求: