AI评测
2025年AI声音克隆软件排行榜推荐 功能区别和优势对比
- 2025-01-20
- 李老师
- AI吧
Hello,又和大家见面了,我是AI吧教学日记的李老师。AI TTS,也就是 AI 语音生成,想必大家都已耳熟能详,在音频生成这片天地中,其应用已然相当成熟,足以成为我们日常工作中的得力助手,为效率提升添砖加瓦。然而,市面上的 AI TTS 项目琳琅满目,各类软件及其搭载的模型更是各擅胜场。
今天,凭借李老师一年多在 AI TTS 领域的深耕细作,精心总结出以下几款应用广泛的 AI TTS 软件,为诸位一一道来、评测剖析。文章聚焦于“语音生成速度、生成的音频质量、声音克隆相似度、声音情绪的复刻”四大关键维度,力求筛选出各领域的佼佼者,为大家指引方向。
需注意,本文评测仅基于原始模型,二次开发或微调后的版本不在讨论之列,闲话少叙,评测正式开始!
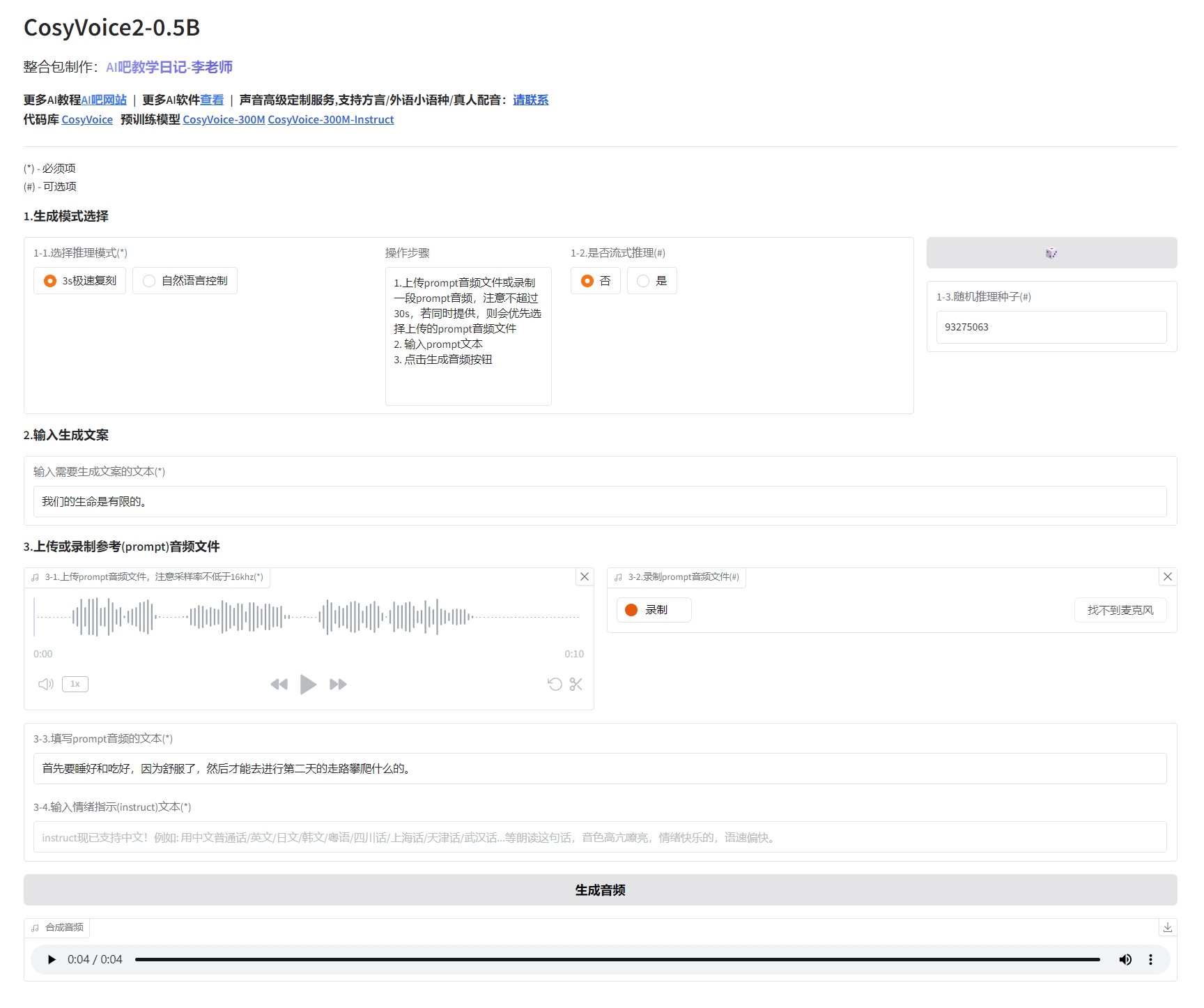
1、CosyVoice 2.0

最低配置:支持 CUDA 的 nVIDIA 显卡,4G 显存
推荐配置:支持 CUDA 的 nVIDIA 显卡,6G 显存
支持语种:中文普通话/英语/日语/韩语/粤语/四川话/上海话/郑州话/长沙话/天津话
语音生成速度:★★★
生成音频质量:★★★★★
声音克隆相似度:★★★★★
声音情绪的复刻:★★★★
CosyVoice 最大的亮色在于,其音色克隆相似度堪称一绝,在原声情绪复刻上亦是可圈可点,独占鳌头。情绪复刻给予 4 星,只因尚有精进空间,未臻完美之境,翘首以盼后来者能突破桎梏,再创新高。
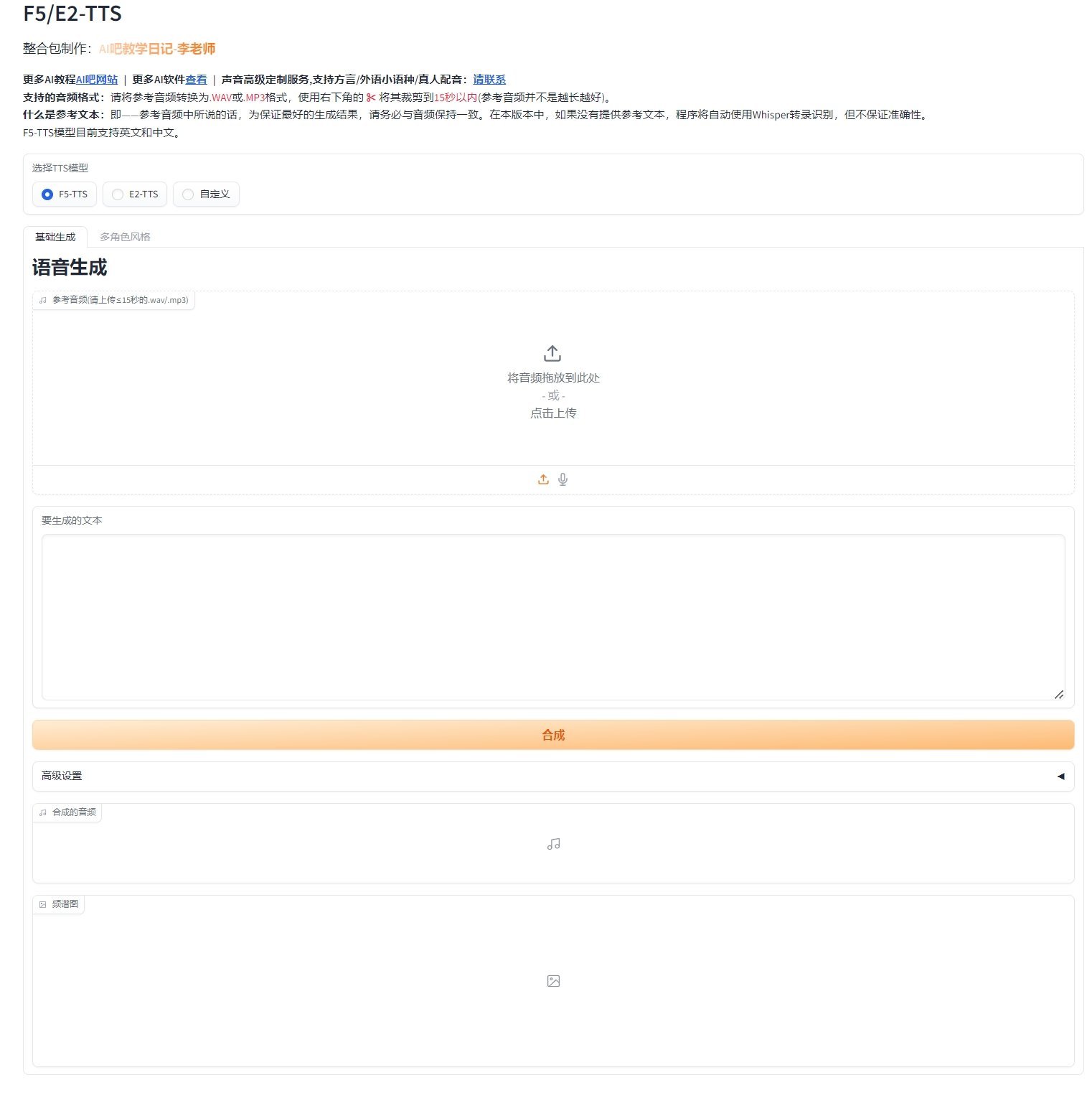
2、F5-TTS

最低配置:无需显卡,CPU亦可推理生成
推荐配置:支持 CUDA 的 nVIDIA 显卡,4G 显存
支持语种:中文普通话/英语
语音生成速度:★★★★
生成音频质量:★★★★★
声音克隆相似度:★★★★
声音情绪的复刻:★★★
F5-TTS 于英文生成领域表现卓越,发音标准程度在本次评测软件中独占鳌头。再者,官方预设的多角色生成模式独具匠心,能够配置多个角色,一次性为多角色、多情绪生成对话式语音,别出心裁。
F5-TTS 支持 CPU 推理模式,对 无显卡/A卡用户 尽显友好。
美中不足的是,当前对语种的支持稍显单薄。
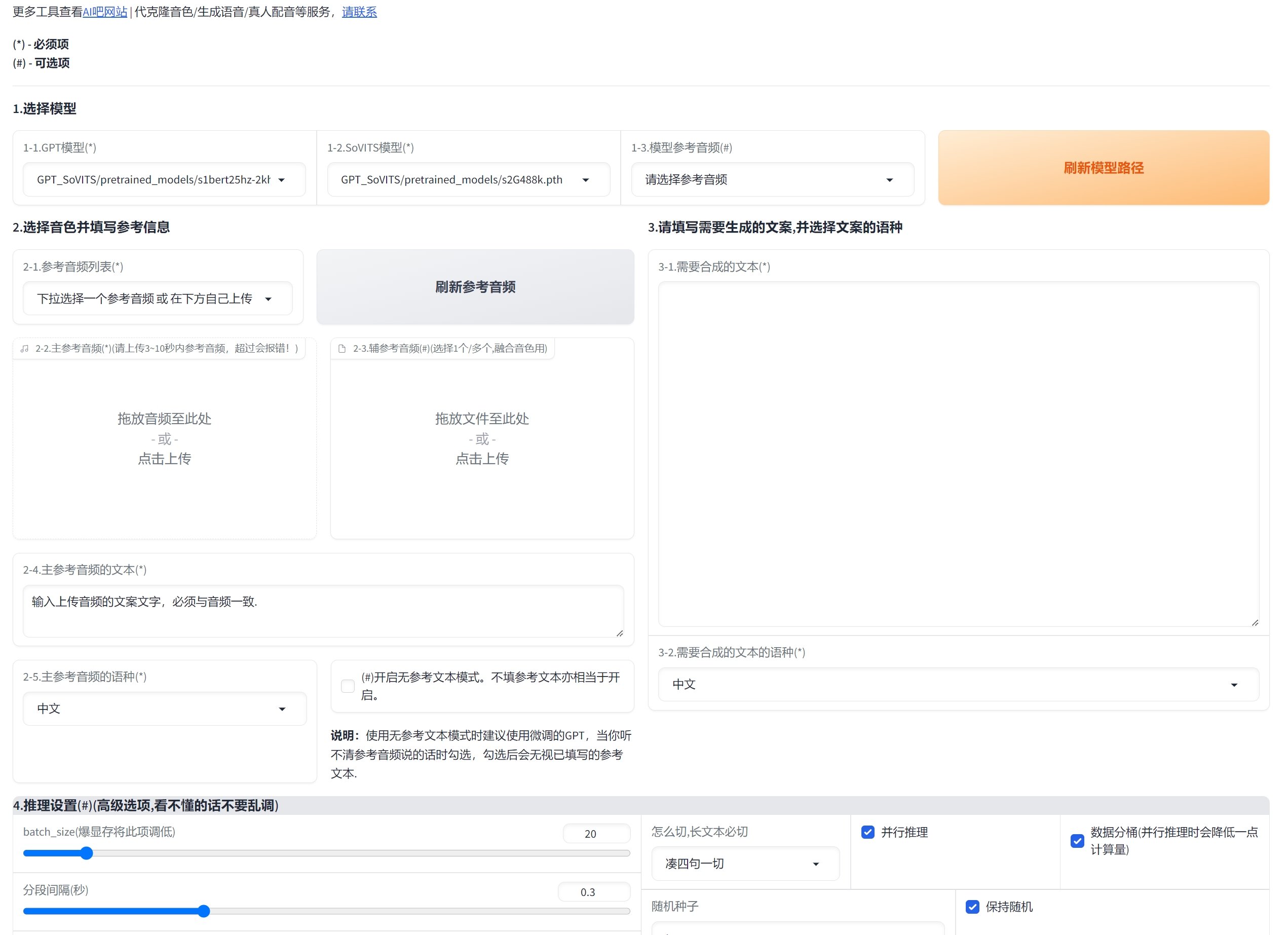
3、GPT-SoVITS-V2

最低配置:无需显卡,CPU亦可推理生成
推荐配置:支持 CUDA 的 nVIDIA 显卡,4G 显存
支持语种:中文普通话/英语/日语/韩语/粤语
语音生成速度:★★★★★
生成音频质量:★★★★
声音克隆相似度:★★★
声音情绪的复刻:★★★★
GPT-SoVITS 的优缺点泾渭分明,优势显著者有二:
其一,语音生成速度一骑绝尘,在本次评测的 AI TTS 中堪称最快。以 RTX 3080 Ti 12G 显卡实测,生成 1000+ 字文案仅需 14 秒,非常离谱。
其二,支持模型训练,GPT-SoVITS-V2 原生支持声音模型训练,只要肯投入时间钻研、训练专属模型,理论上而言,其情绪复刻效果能在四者中登顶,毕竟你可以不停地添加音频数据集,持续强化模型。
缺点亦不容忽视,zero-shot 推理时,原声音色相似度欠佳,生成音频质量偶有杂音、吞字乱象,需要反复抽卡。
值得一提的是,本文呈现版本,为我二次开发,在官方功能基础上优化代码,让生成速度更上一层楼;新增变声器、指定 AI 中文拼音音调的自定义发音,有效解决 AI 中文多音发音的问题。
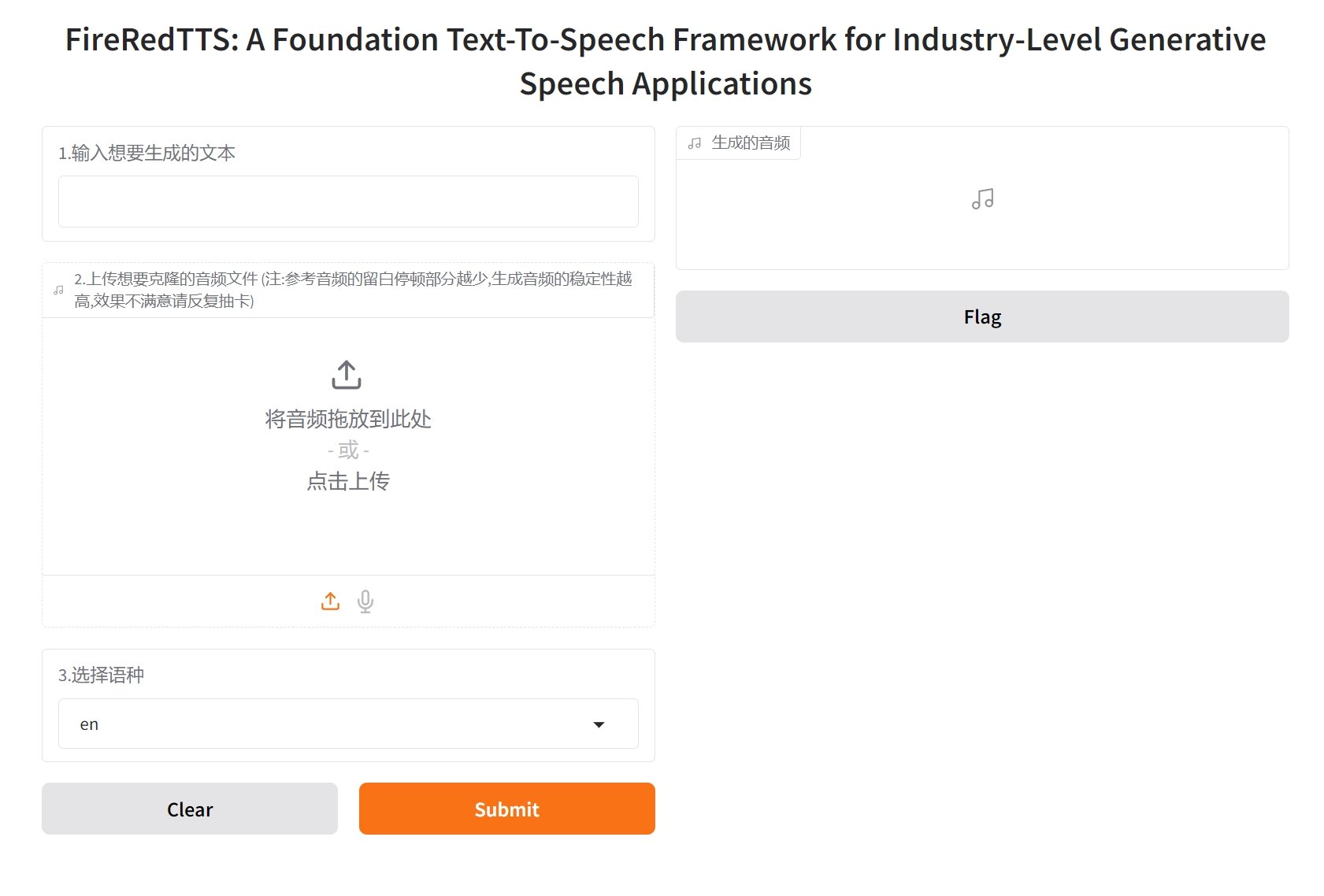
4、FireRed-TTS

最低配置:支持 CUDA 的 nVIDIA 显卡,4G 显存
推荐配置:支持 CUDA 的 nVIDIA 显卡,6G 显存
支持语种:中文普通话/英语/日语/韩语/粤语
语音生成速度:★★★★
生成音频质量:★★★★
声音克隆相似度:★★★★
声音情绪的复刻:★★★★
小红书团队开源的这款 AI TTS,界面设计极简至臻,聚焦单一却极致的语音克隆生成功能,摒弃繁杂参数,仅需上传一段参考音频,即可凭借 zero-shot 技术克隆生成饱含原声音色与情绪的语音,仿若开启便捷之门,对新手小白踏入 AI TTS 领域而言,无疑是最佳引路人。
四款软件各有千秋,无论你是追求极致音色克隆的专业人士,还是初涉 AI TTS 领域的新手,可以籍由本文选一款自己中意的,或是干脆四款照单全收,为为自己带来更高效的创作。
关注AI吧教学日记!我们将持续为你深挖好用好玩的 AI 教学。