AI教程
clearvoice整合包怎么安装使用 clearvoice使用教程
- 2025-03-07
- 朴老师
- AI吧
哈喽大家好,这里是AI吧教学日记的朴老师,clearvoice作为一款能够进行人声增强以及多人声分离的音频处理工具,其实用性可以说是毋庸置疑的,但是很多小伙伴拿到了整合包,却不知道clearvoice整合包怎么安装使用,接下来我将从头开始教学,一步一步教学如何使用该软件。
整合包下载地址:
ClearVoice v2.0整合包下载地址:
https://ai8.net/fuli/2025/0102/605.html
https://ai8.net/fuli/2025/0102/605.html
一、语音增强(降噪):
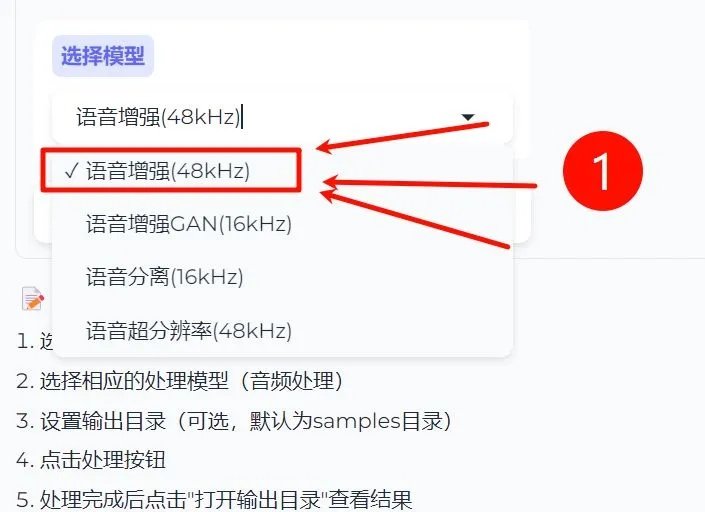
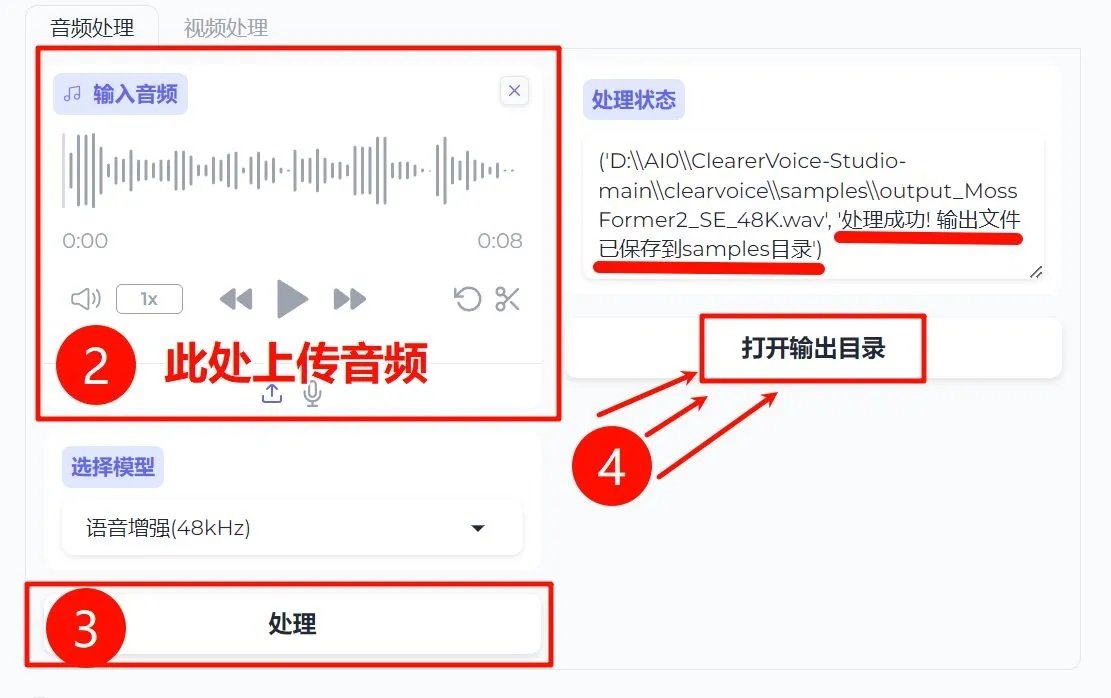
①选择模型:模型选择为[语音增强(48kHZ)]或[语音增强CAN(16kHZ)],建议选择[语音增强(48kHZ)],输出效果更好,如果原采样率为48khz,输出则不会变,如原采样率为16/44kHz,选择48kHZ,会重采样为48kHz,实测效果提升明显。
②上传需要处理的音频:直接点击上传,或将音频直接拖入[输入音频]位置。
③点击处理,等待处理。
④当[处理状态]显示"处理成功! 输出文件已保存到samples目录"时,点击下方按钮[打开输出目录],即可进入到保存目录。
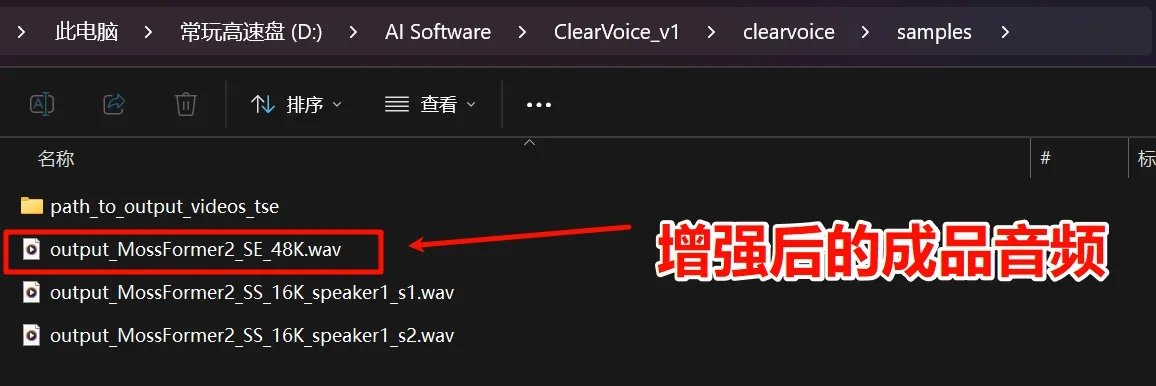
⑤进入输出文件夹后,双击打开[output_MossFormer2_SE_48K.wav]即可试听增强后的音频,保存则需拷贝至其他文件夹,若重新处理会直接覆盖该文件。
二、语音分离(分离两人对话声音)
音频处理:
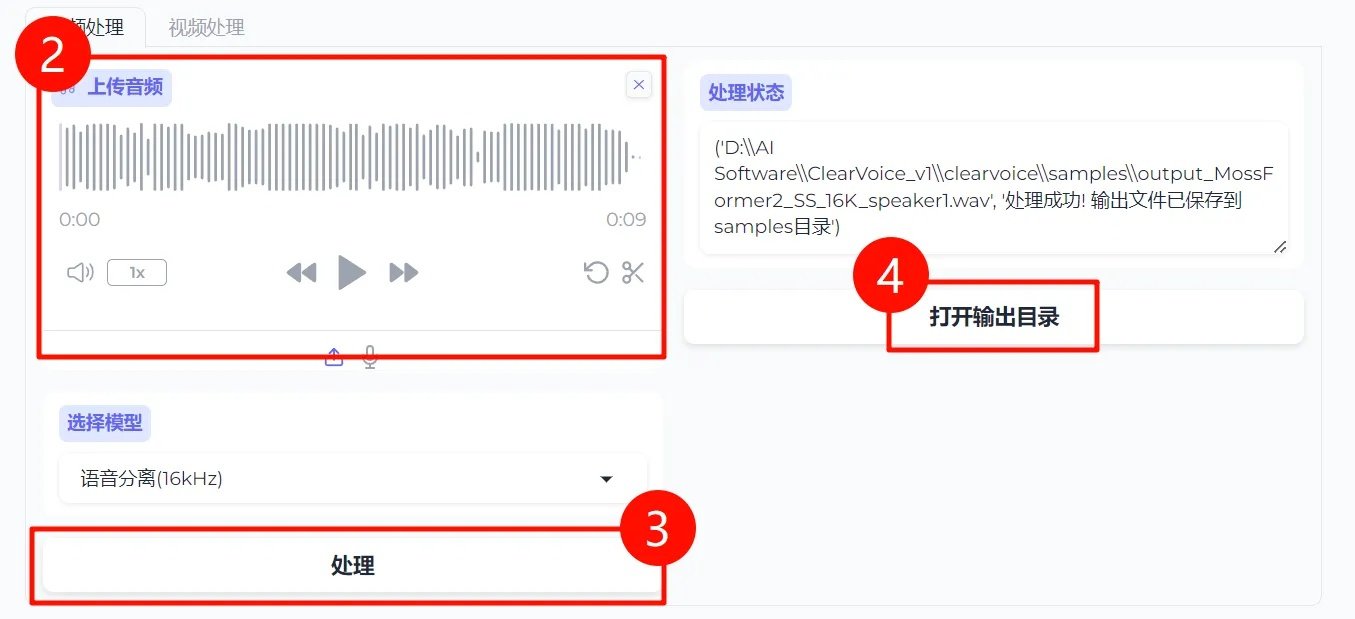
①选择模型:模型选择为[语音分离(16kHZ)]。

②上传需要处理的音频:直接点击上传,或将音频直接拖入[输入音频]位置,要求该音频人声不能超过两人,最多支持两人人声分离,超过俩人则无法分离。
③点击处理,等待处理。
④当[处理状态]显示"处理成功! 输出文件已保存到samples目录'"时,点击下方按钮[打开输出目录],即可进入到保存目录。
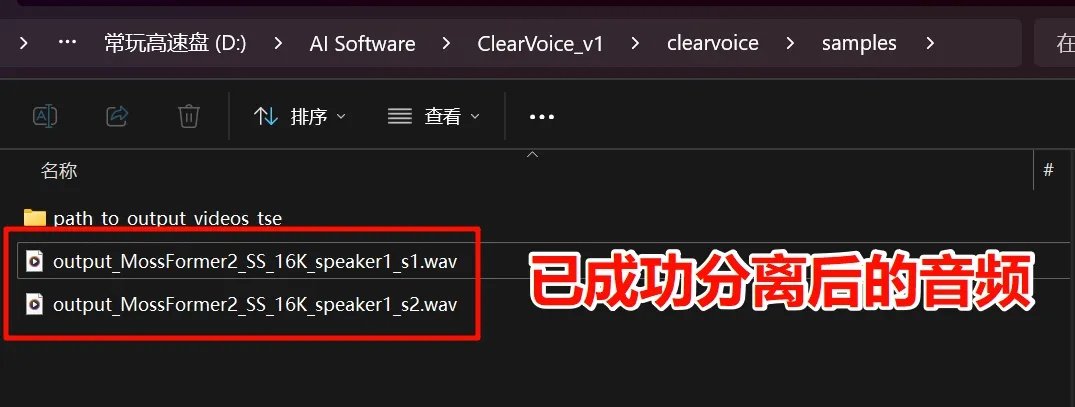
⑤进入输出文件夹后,可以看到以下两段音频文件,[output_MossFormer2_SS_16K_speaker1_s1.wav]、[output_MossFormer2_SS_16K_speaker1_s2.wav]分别为已分离出来的两段人声,双击即可试听播放,如需保存,可将两段音频拷贝至其他文件夹,每次分离新的音频,都会直接覆盖音频文件。
说明,分离后的音频采样率为16kHz,建议用语音增强/语音超分辨率再处理重采样一遍。
视频处理:
clearvoice的视频处理目前还在beta测试阶段,如若需要处理视频音频,可使用以下该方法「另辟蹊径」,这里以剪映为例。
①打开剪映、点击开始创作。

②导入需要处理的视频,同音频处理模式,人声不能超过两人。
③将素材拖入工作导轨,选中素材后,鼠标右键,选择分离音频。
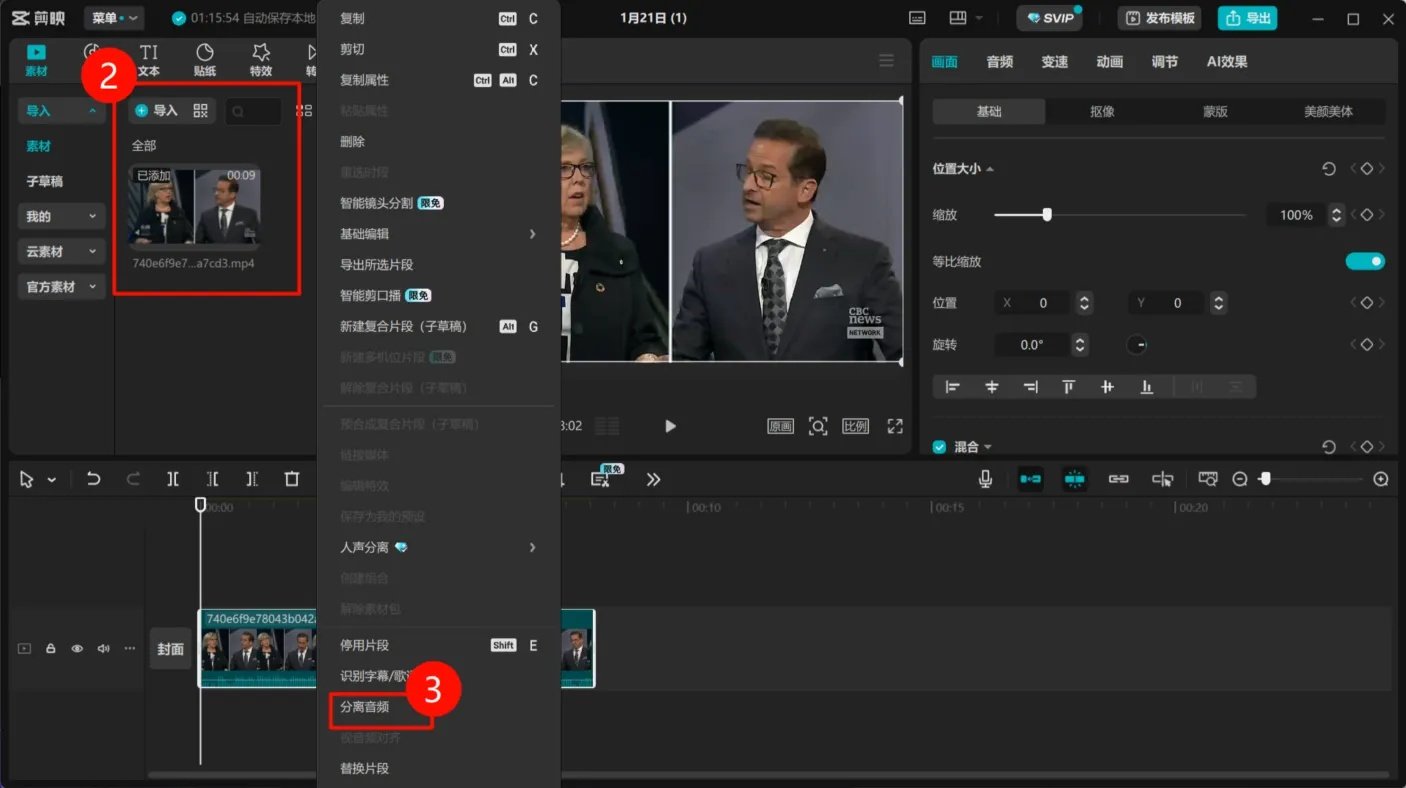
④点击右上角导出,勾选音频导出选项,导出格式选择wav格式后,进行导出。
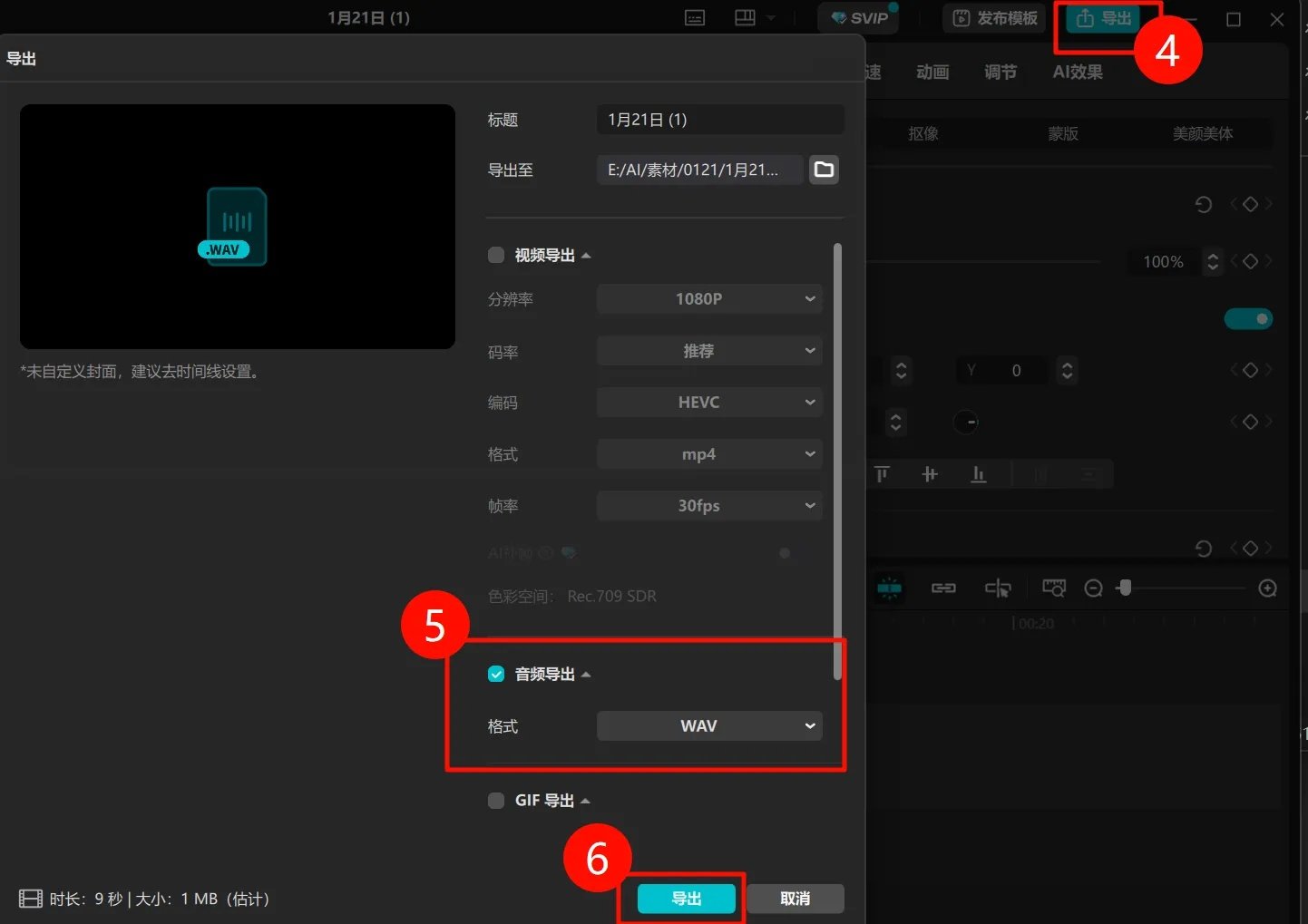
⑤音频导出完成后,点击【打开文件夹】,后续步骤直接按照音频处理步骤进行处理即可。
三、语音超分辨率:
超分辨率:将原有低音质音频提升至高音质音频,音频细节对比原音频更加细腻。
①选择模型:模型选择为[语音超分辨率(48kHZ)]。
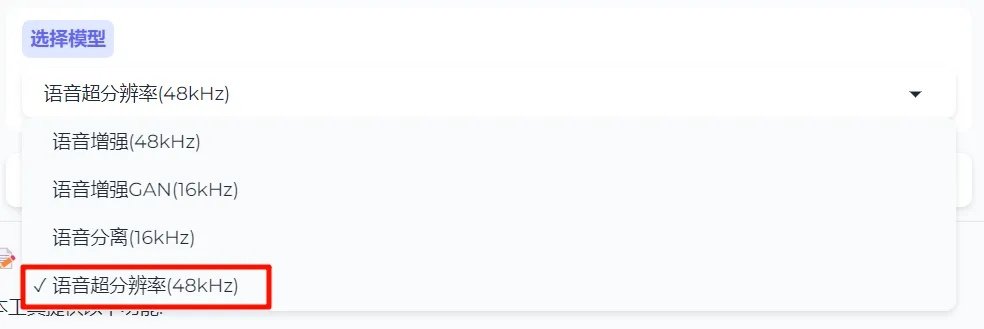
②上传需要处理的音频:直接点击上传,或将音频直接拖入[输入音频]位置。
③点击处理,等待处理。
④当[处理状态]显示"处理成功! 输出文件已保存到samples目录'"时,点击下方按钮[打开输出目录],即可进入到保存目录。
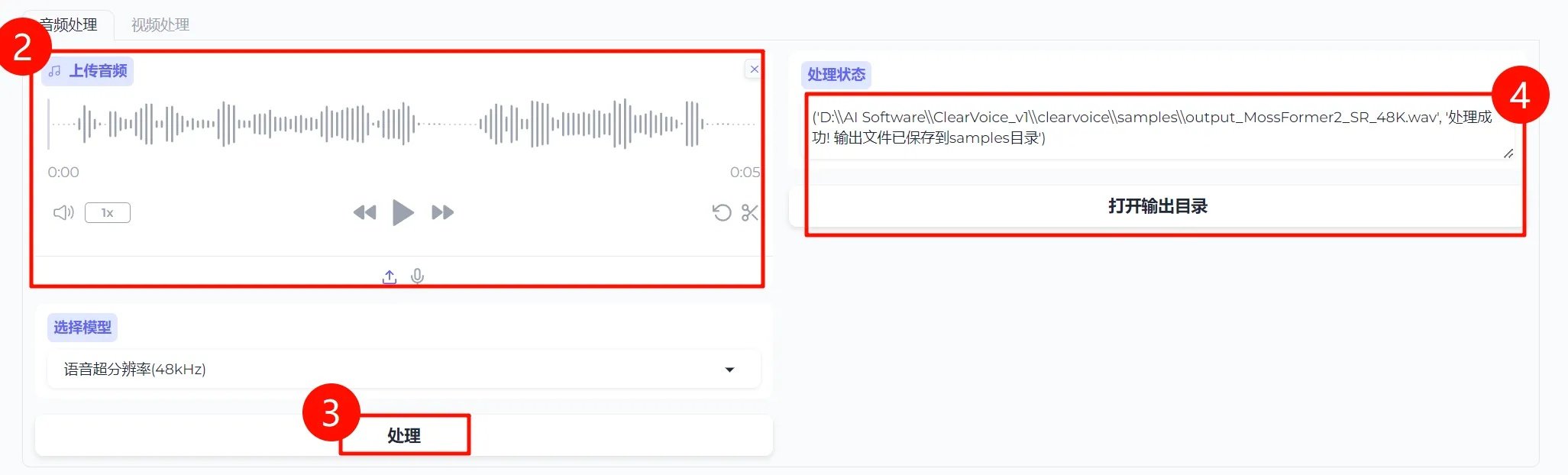
⑤进入输出文件夹后,双击打开[output_MossFormer2_SR_48K.wav]即可试听增强后的音频,保存则需拷贝至其他文件夹,若重新处理会直接覆盖该文件。
四、其余注意事项
1、上传的音频格式仅支持[.wav, .flac, .mp3, .aac] 等。
2、上传的视频格式仅支持[.mp4, .avi, .mov, .webm] 等。
到这里整个使用教程就结束了,使用是不是很简单呢?如果你还遇到其他有关ClearVoice的问题无法解决,可以持续关注AI吧网站,我们会持续为大家更新最新教学内容。