AI教程
Ai让照片说话教学!EchoMimic图片转视频
- 2024-07-22
- Arjun
- 本站原创
今天带大家玩的是大阿里蚂蚁团队开源的新项目——EchoMimic。
项目官网:https://badtobest.github.io/echomimic.html
Github:https://github.com/BadToBest/EchoMimic
Hugging Face:https://huggingface.co/BadToBest/EchoMimic
arXiv技术论文:https://arxiv.org/html/2407.08136

EchoMimic可以分析音频的波形,分析出音频的情绪,然后通过整合图像面部的特征点,生成出更为逼真、自然的动态视频。用人类的话来总结就是——牛逼
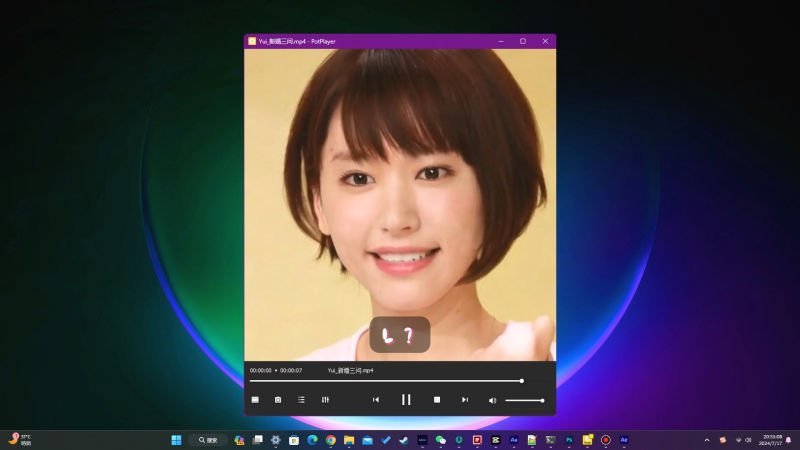
EchoMimic的视频生成,依赖cuda的加速,请确保你的电脑有独立显卡,并且已经安装cuda。
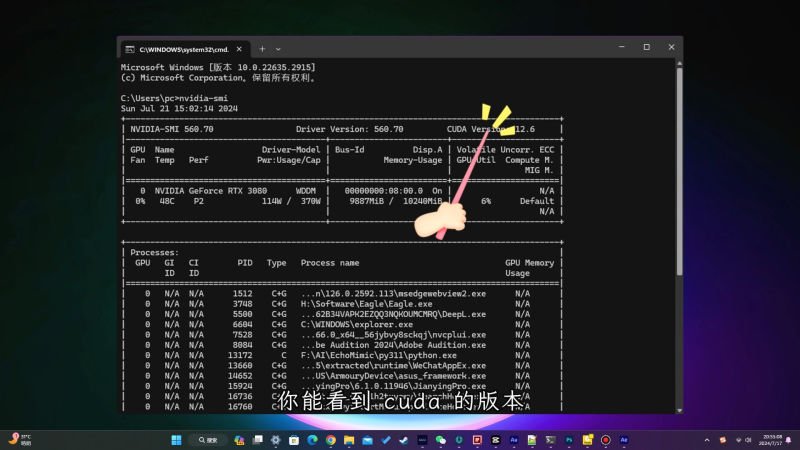
按Ctrl+R,呼出运行窗口,输入「cmd」,输入「nvidia-smi」
右上角能看到cuda的版本代表可以正常运行。
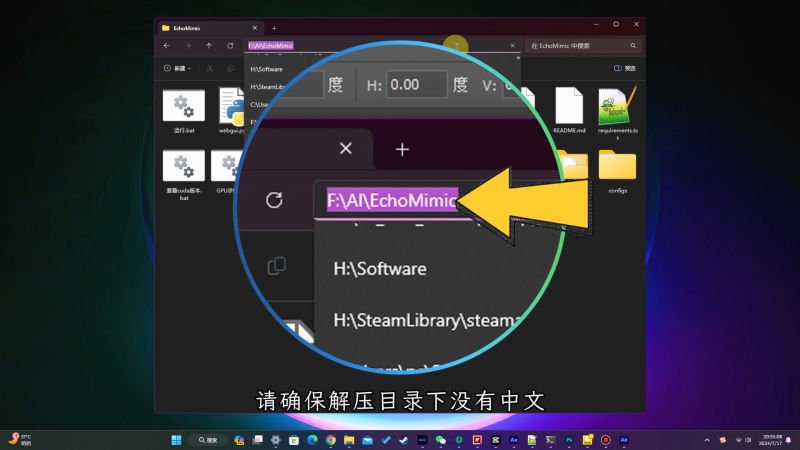
下一步,解压整合包到任意目录,请确保解压路径下没有中文。
打开目录下的「运行.bat」文件,等待程序释放相关环境,完成后会在你的浏览器自动打开EchoMimic的webui界面。
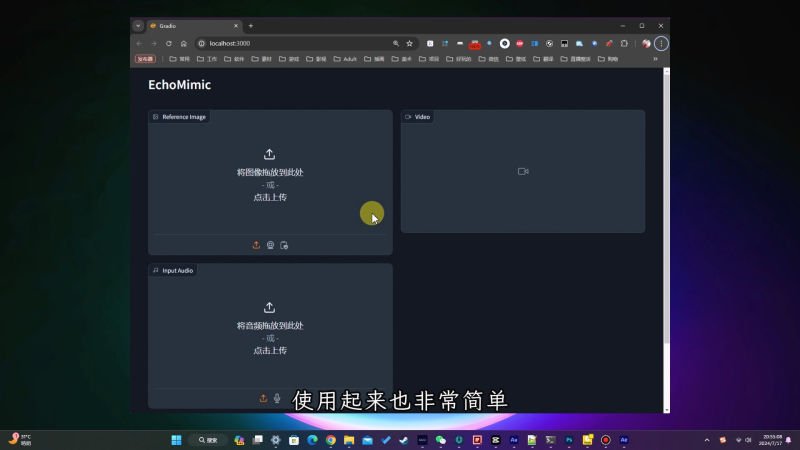
使用起来非常简单,在此处上传图像,接着上传一段音频
点击「Configuration」展开配置选项。
用width和height,控制生成视频的宽高;
如果你在生成的过程中,出现了脸部错位,或是唇形没有覆盖到的情况,请尝试调整这几个选项:
CFG用于评估生成的视频与图片的一致性程度,如果你生成的视频与图像大相径庭,请尝试提高CFG的数值
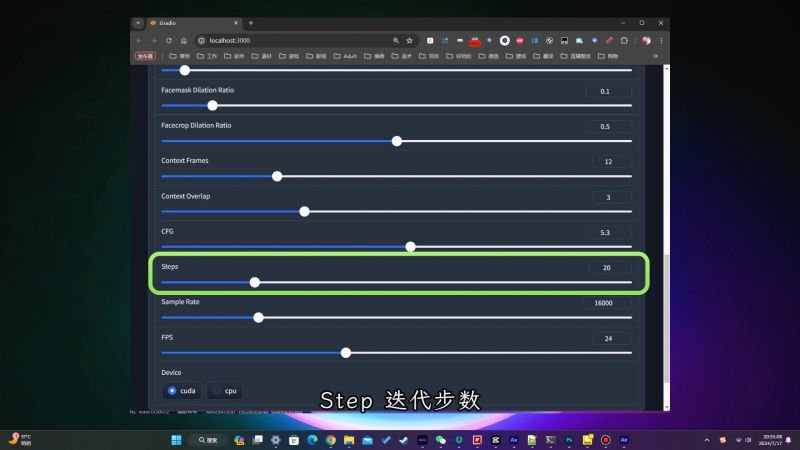
Step迭代步数,将直接影响你生成视频的质量,但同时也会非常显著地增加生成的时间,默认为30,如果你生成的视频一直没问题,可以尝试降低步数来缩短生成的时间,反复调整直到最合适的步数。
FPS帧数推荐设置为24~60这个范围。
最后,点击生成即可。
OK,本次的教程就到这里,关注AI吧,我会持续进行ChatTTS语音克隆模型的版本更新,下次再见,拜拜。