AI教程
ChatTTS克隆声音教程?给我5秒钟,偷走你的声音
- 2024-07-09
- Arjun
- 本站原创
听腻了默认的ai配音?现在,无论是模仿名人,还是复刻亲友的声音,ChatTTS都能助你一臂之力。现在跟我一起,来教你用任何你喜欢的声音,来讲述你的故事!
我们先来看一段demo,这是我用ChatTTS克隆周深的声音,生成的。

下面开始教学。
第一步、声音样本的准备
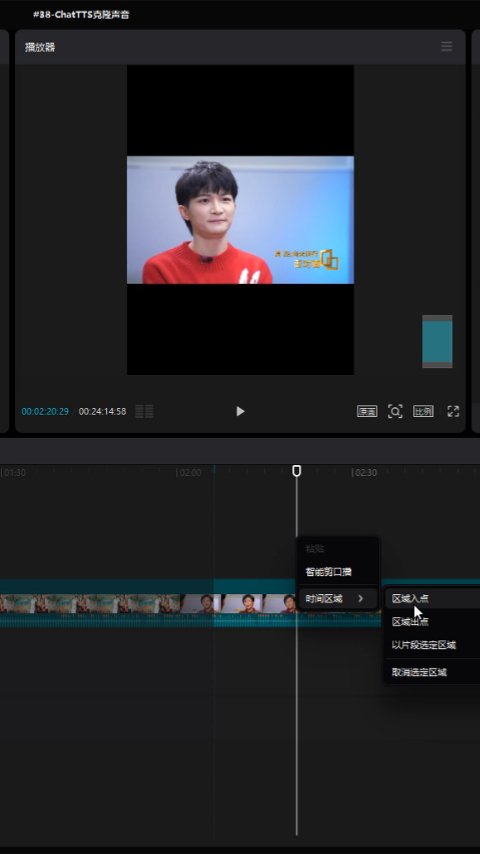
首先,我们要准备一段样本音频,这里就拿周深的一段采访举例。
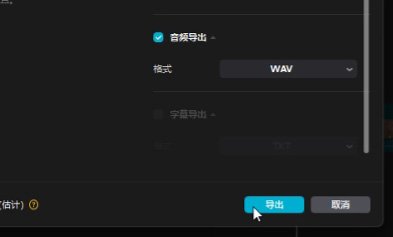
把视频丢进剪映,标记一个入点,再给一个出点,按ctrl+m导出,只勾选音频wav导出。
第二步、将声音转化成ChatTTS的音色种子
打开ChatTTS音色克隆的页面:http://region-9.autodl.pro:41137/。
上传刚刚导出的wav。克隆模型版本这边,我推荐选择v4_mix_200k的这个,v7和v7.1,你也可以尝试。
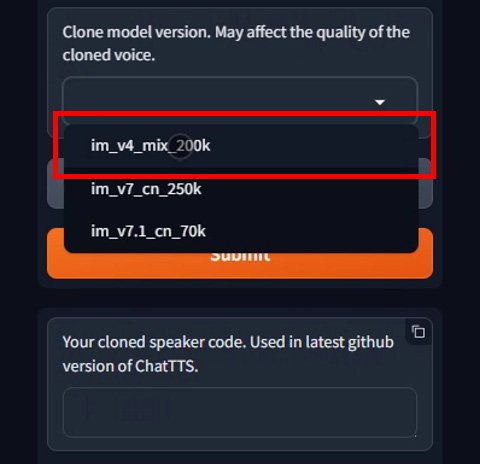
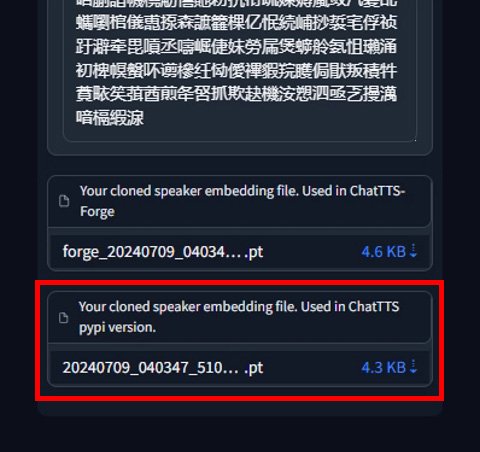
再点击Submit提交生成音色种子,生成完毕后,选择pypi这个版本下载保存到本地。
第三步、语音生成
运行ChatTTS一键整合包目录下的「运行.bat」,稍等片刻,会在你的浏览器打开ChatTTS的webui界面。
一键整合包,移步此处下载:https://www.yuque.com/chengby/bye72a/hxf81w24ocga8hvi?singleDoc#
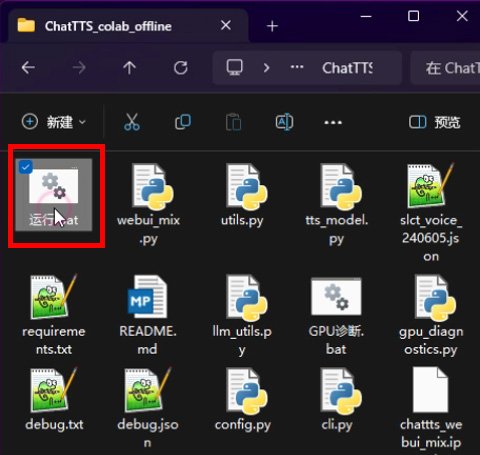
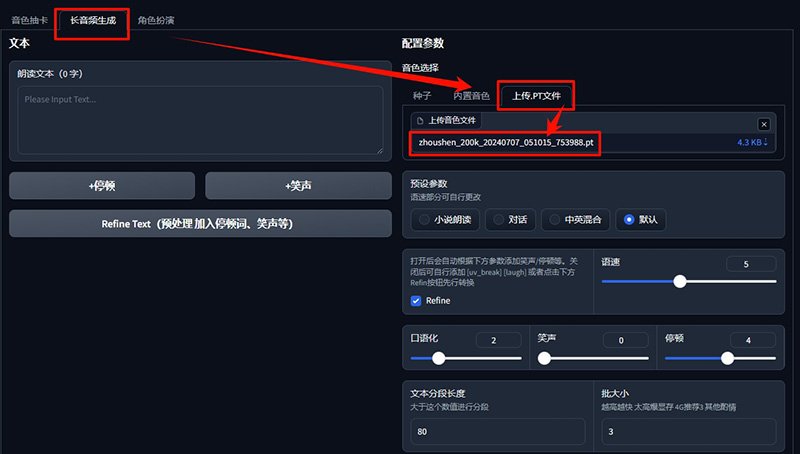
切换到长音频生成tab,在「音色选择」这里,上传刚刚保存的音色种子文件。接着粘贴你的文本,点击生成,就搞定了。
ChatTTS的声音克隆目前还是测试版本,从克隆出来的声音相似度来看,感觉是不如GPT-SoVITS的。
但优势也很明显,得益于ChatTTS强大的,模拟真人说话的语境的推理能力,在生成过程中,我只是给了文本,并没有上传周深的原版声音,完全是ai自行推理生成,就自带了喘气、和停顿断句这些真人的语境。
OK,本次的教程就到这里,关注AI吧,我会持续进行ChatTTS语音克隆模型的版本更新,下次再见,拜拜。