AI教程
ChatTTS最新一键整合包!固定音色多角色读小说干货教学,10分钟长语音生成
- 2024-07-06
- Arjun
- 本站原创
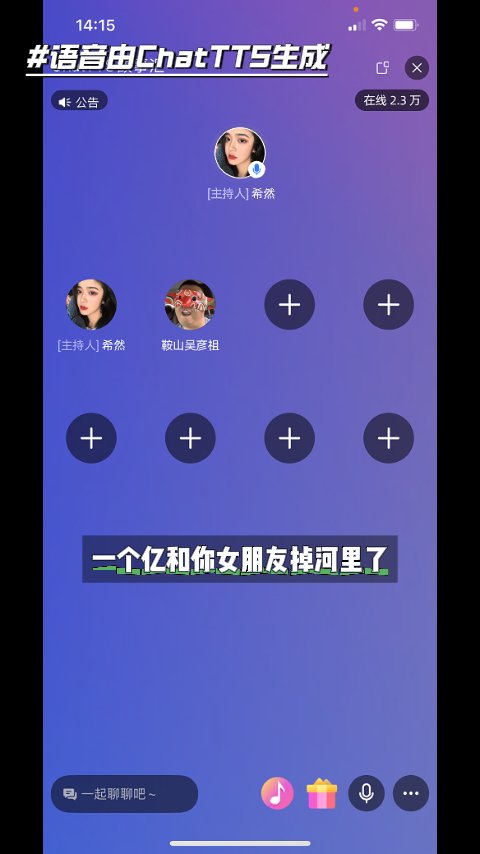
今天我们来学习,怎么用ChatTTS来固定你喜欢音色、学会了可以做什么呢?可以分角色朗读小说,生成多人对话,我们来看个例子。
第一步,固定音色
打开网址:https://modelscope.cn/studios/ttwwwaa/ChatTTS_Speaker/
这里有成千上万个用ChatTTS生成的音色,这里一般推荐选择rank_multi多句文本,以及rank_long长语句文本稳定性得分比较高的声音。
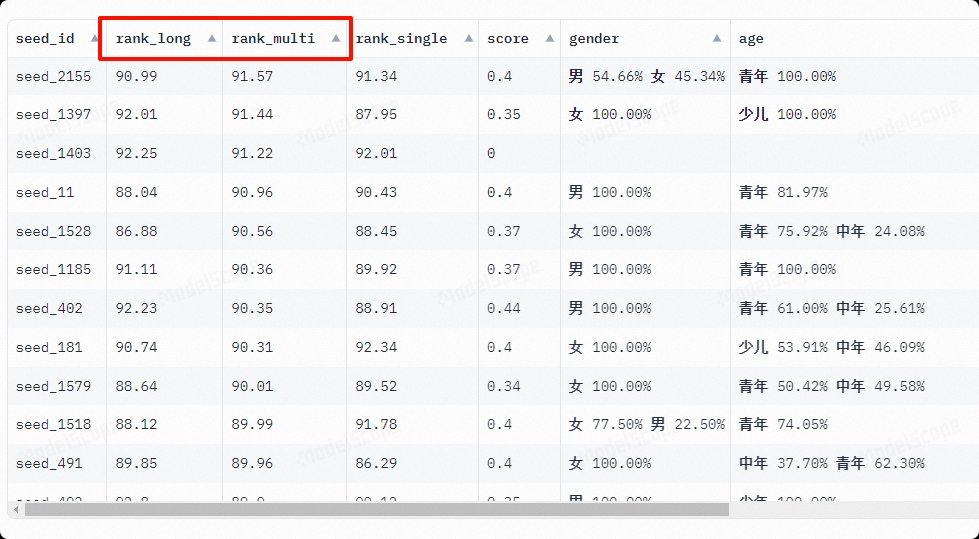
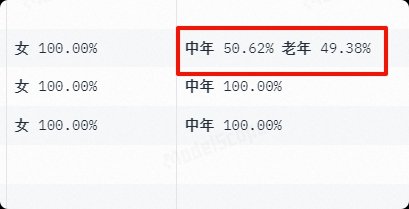
后面还有声音的性别特征,比如你的小说中有老奶奶的声音,就要选择[老年+女性 百分比高]的声音。
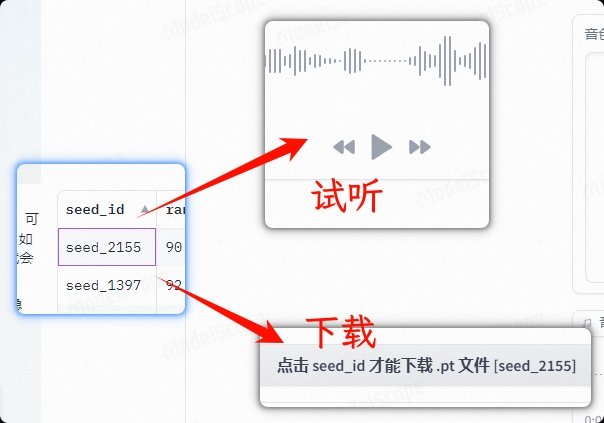
轻点第一列的seed_id,然后试听,喜欢的话点击上面的下载按钮,然后给.pt音色文件命个名,方便你的记忆。
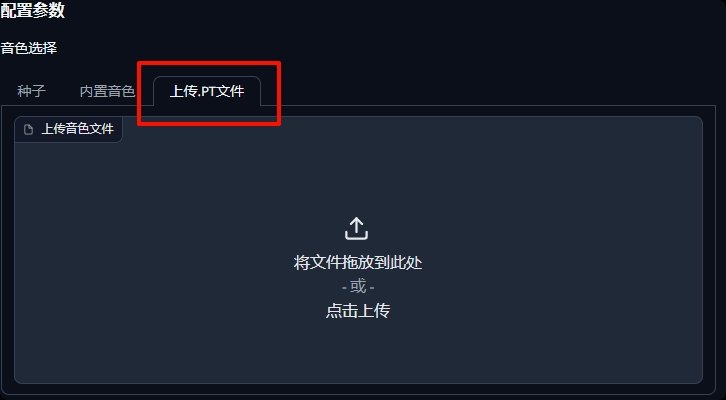
接着,回到ChatTTS,上传刚刚下载的.pt文件,这样音色就固定了。注意,ai文字生成语音,存在抽奖的可能性,即便你用pt固定住了音色,也可能出现偏差,因此你需要多生成几次来保证一致性。
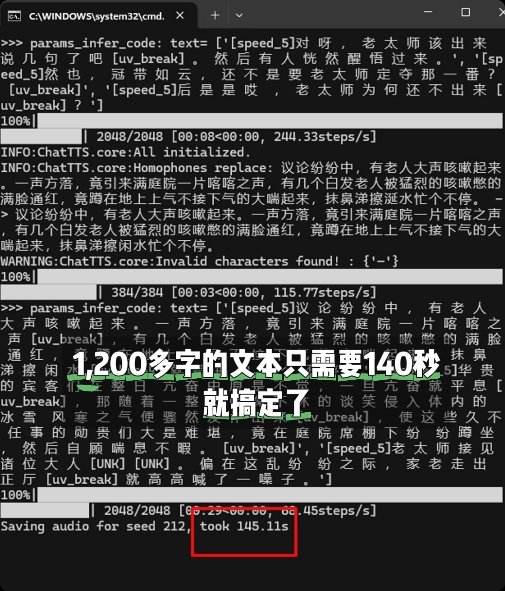
别担心,本次新版本,大幅优化了生成速度,[展示生成时间的命令行窗口] 1200多字的文本,只需要140秒即可搞定,是不是惊呆了?
你也可以切换「内置音色tab」这里内置了一些稳定性比较的声音供你选择。
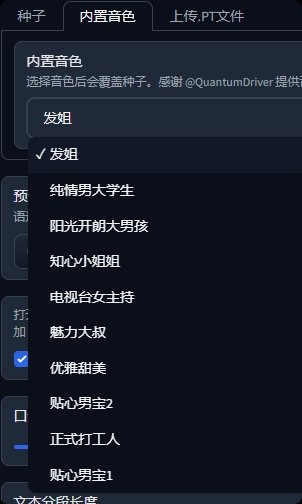
第二步,控制ai语境
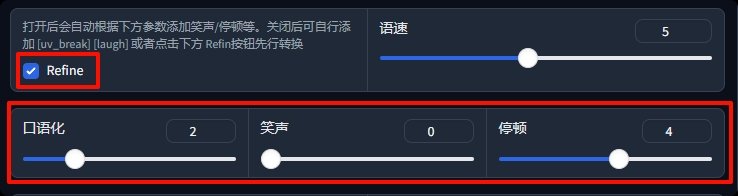
首选勾选Refine,反选的话,后面的参数会全部失效,注意一下。
口语化,就是添加一些「恩~啊~这个~那个~啥啊」之类的语气词;
笑声,就是ai模仿人类的笑声,这个算是ChatTTS的杀手锏,生成出来的连贯性非常好;
停顿,ai会模拟人的肺活量,在说话中加入停顿,听起来会更真实。
滑块拉的越大,随机加入这些情绪的可能性就越高。正因为随机性,ai可能会在不合适的地方,乱加情绪词。遇到此类情况,你可以先反选Refine,然后手动通过语法[uv_break] [laugh]来手动控制ai语境。
这里也预设了一些语音情景来供你使用,比如小说的朗读,会完全去除不需要的口语化和笑声。
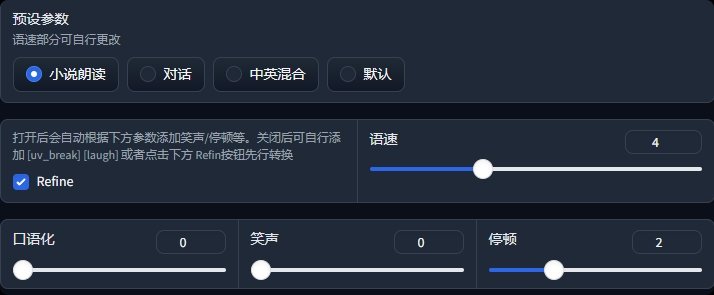
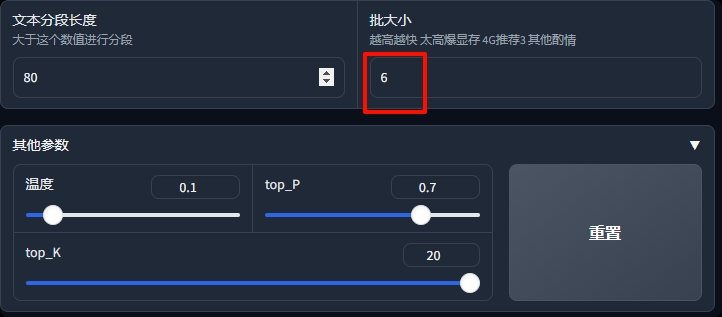
下面,文本分段长度保持默认;批大小,数值越高,语音生成的速度越快,4G显存默认为3,你可以根据你的显存大小来调整。
其他参数中,这三项,都是对ai语音的情感度调整,这里就不展开,你可以自行尝试。
第三步、语音生成
选择一个生成情景,粘贴你的文本,选择Refine Text,ai会自动处理你的文本,在合适的地方创建停顿和笑声。
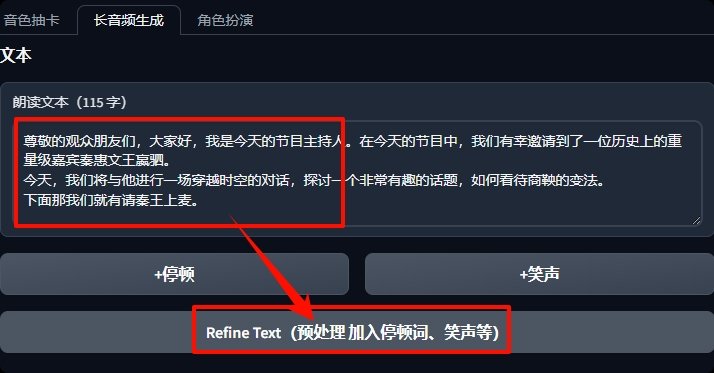
注意,此选项仅供新手使用,如果你想要一段以假乱真的ai语音,必须充分理解ChatTTS情绪控制语法的使用,并根据对话情景,手动控制ai情绪,比如说我加入了情绪控制后的的文本。

怎么样,今天的内容你学会了吗?后续,我将为各位带来,ChatTTS如何克隆声音;一次生成,怎么控制多角色的声音的教程,非常适合小说的朗读。
关注 ai8,我会每天分享一些奇趣好玩的 AI 工具给大家。