AI教程
云端AI如何训练 AI孙燕姿复刻指南
- 2023-10-18
- 六六
- 本站原创
最近AI孙燕姿的话题一度成为年度爆款,大家也在纷纷开启脑洞,想要创造出专属的AI歌手。但脑洞是有了,我们好像还缺少一些实操。想要复刻AI孙燕姿,我们应该怎么做呢?
用指定的音色来点歌,合成完美变身音乐。相信小伙伴们已经开始蠢蠢欲动了。不过真正的考验还在后面,接下来,小编就来介绍如何训练云端AI,生成特定声音。

AI孙燕姿复刻指南:
1. 选择autodl显卡,准备训练(云端训练)
2. 训练模型,获得数据(云端训练)
3. 歌声转换,保存模型(云端推理)
1. 选择autodl显卡,准备训练(云端训练)
·在autodl上选择一个便宜的显卡购买
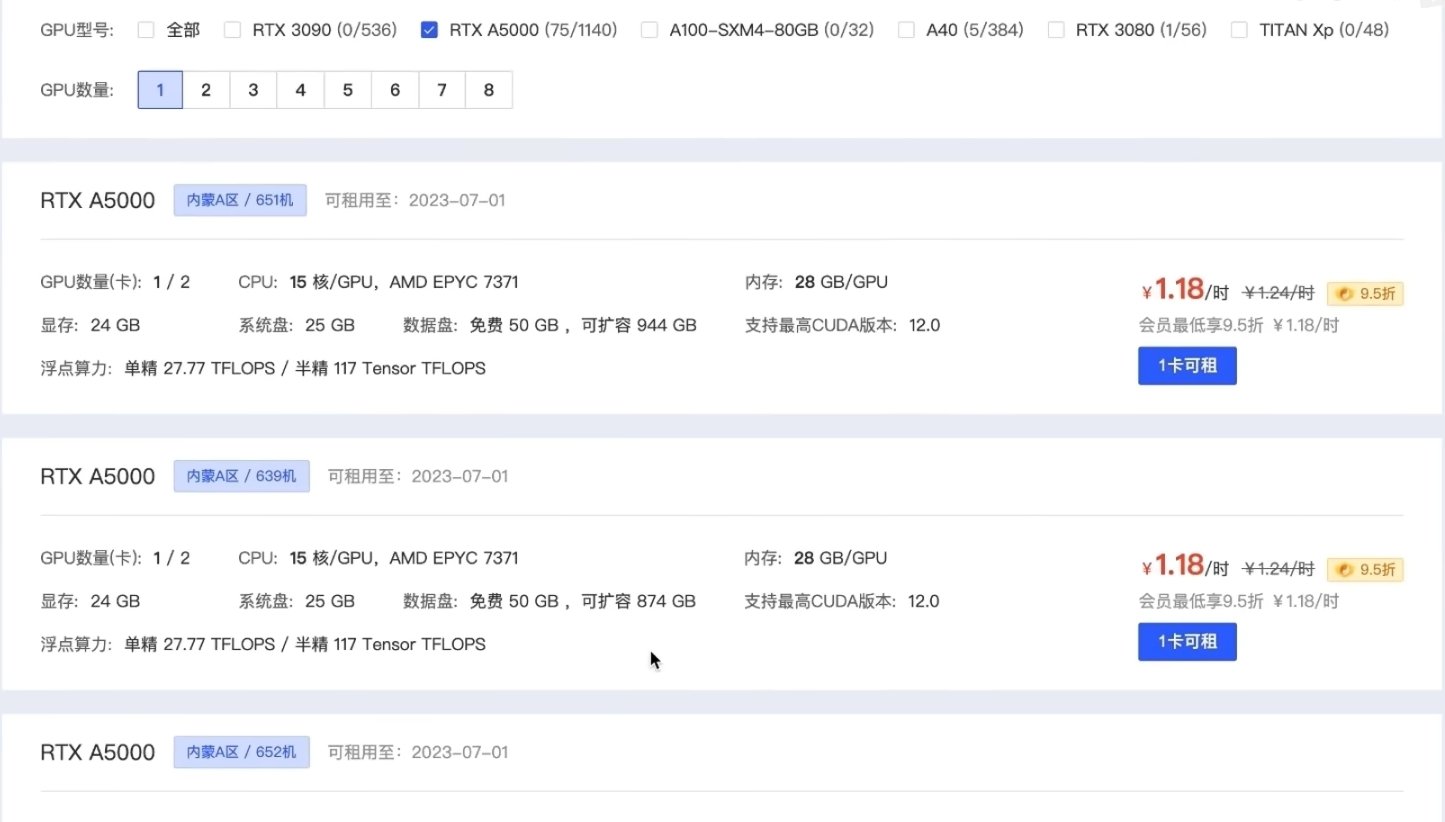
·选择最下面的镜像进入altodl RVC web UI的镜像网页
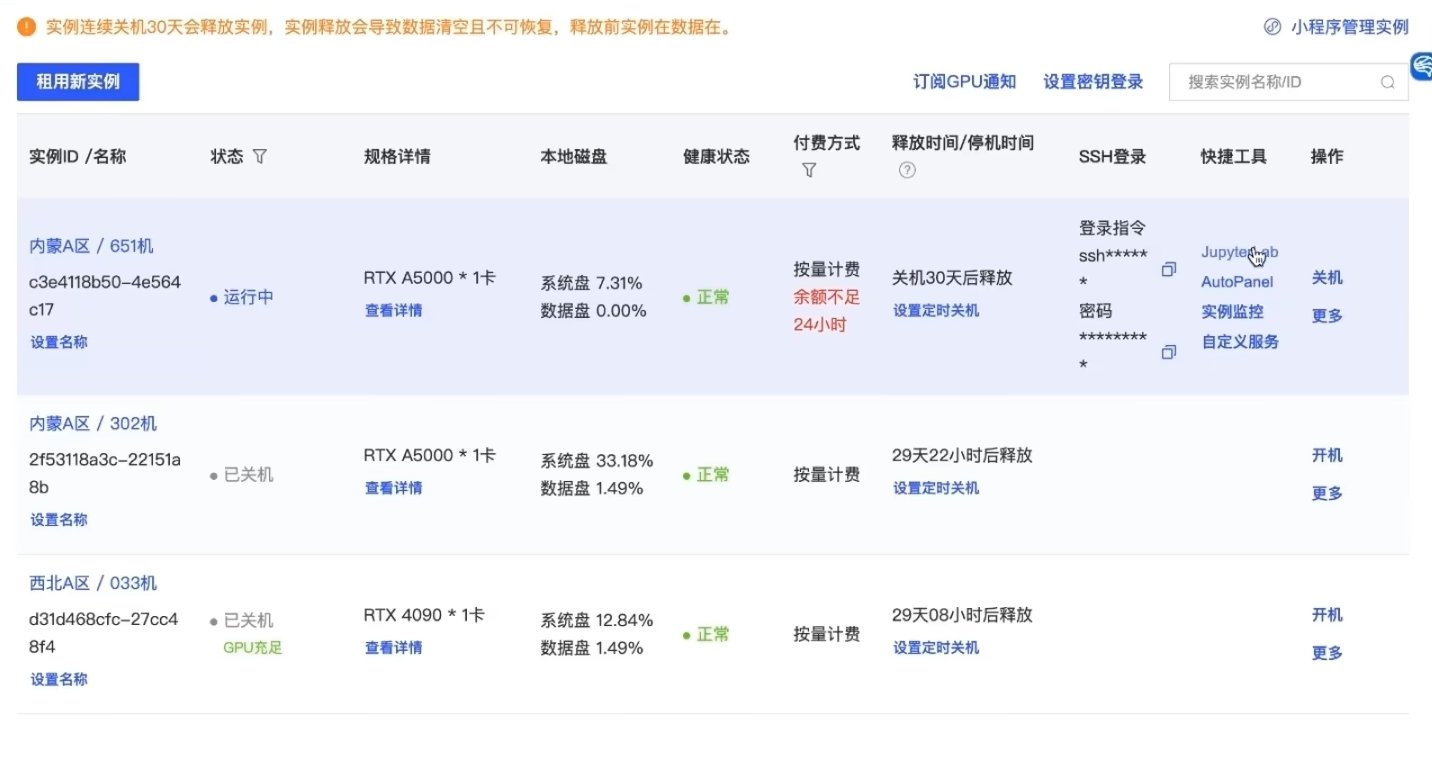
·进入网页后,点击AItodl创建容器,进入控制台
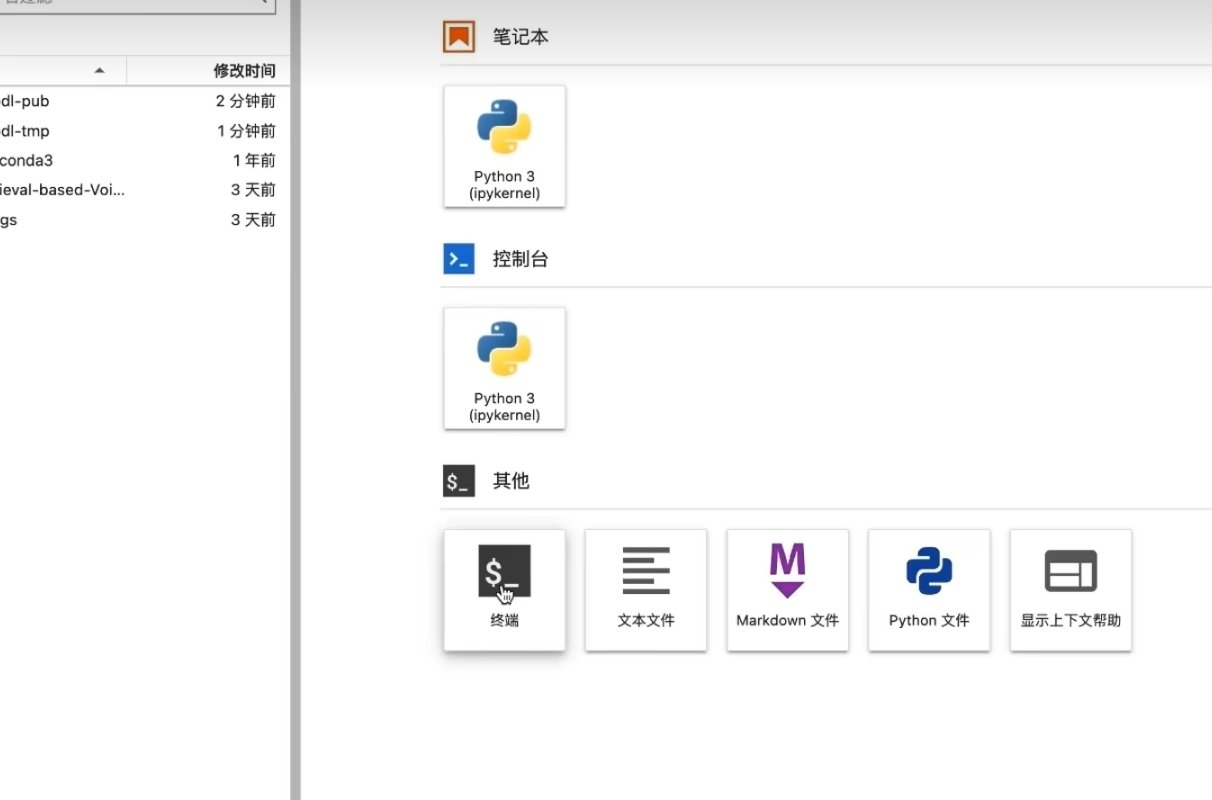
·依次点击jupyterlab、终端,并输入镜像网页提供的命令即可开启RVC的web UI
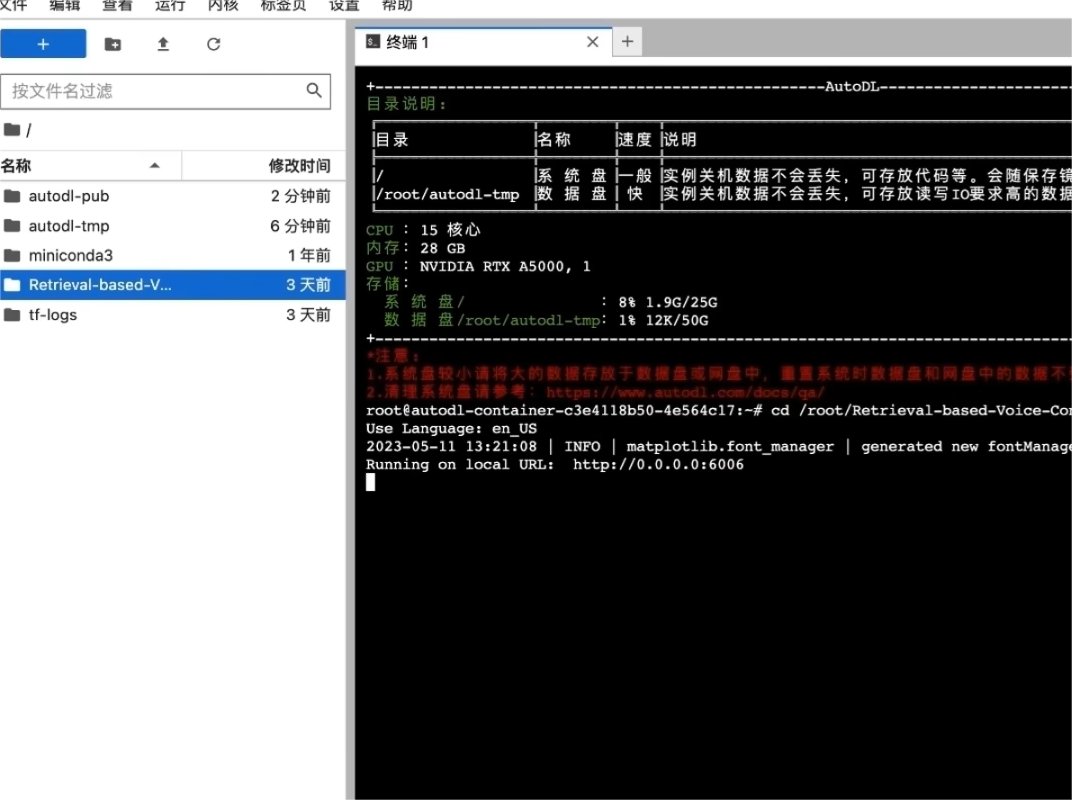
·等待控制台出现6006这行网址时,就可以通过altodl的后台点击自定义服务,用浏览器进入web了

·我们将数据上传到altodl的实例内
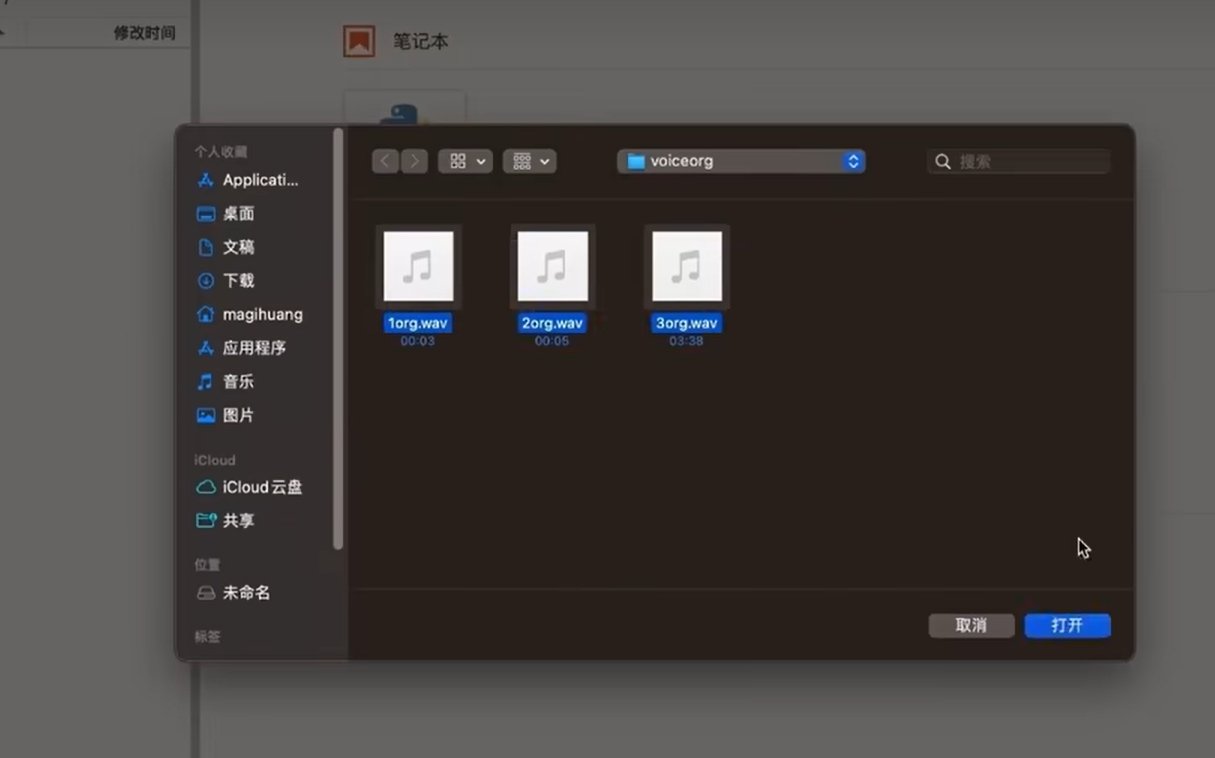
创建文件夹用于存放处理前的训练数据,只需要将数据从本地拖入到云端即可。
·复制该文件的路径,进入web UI
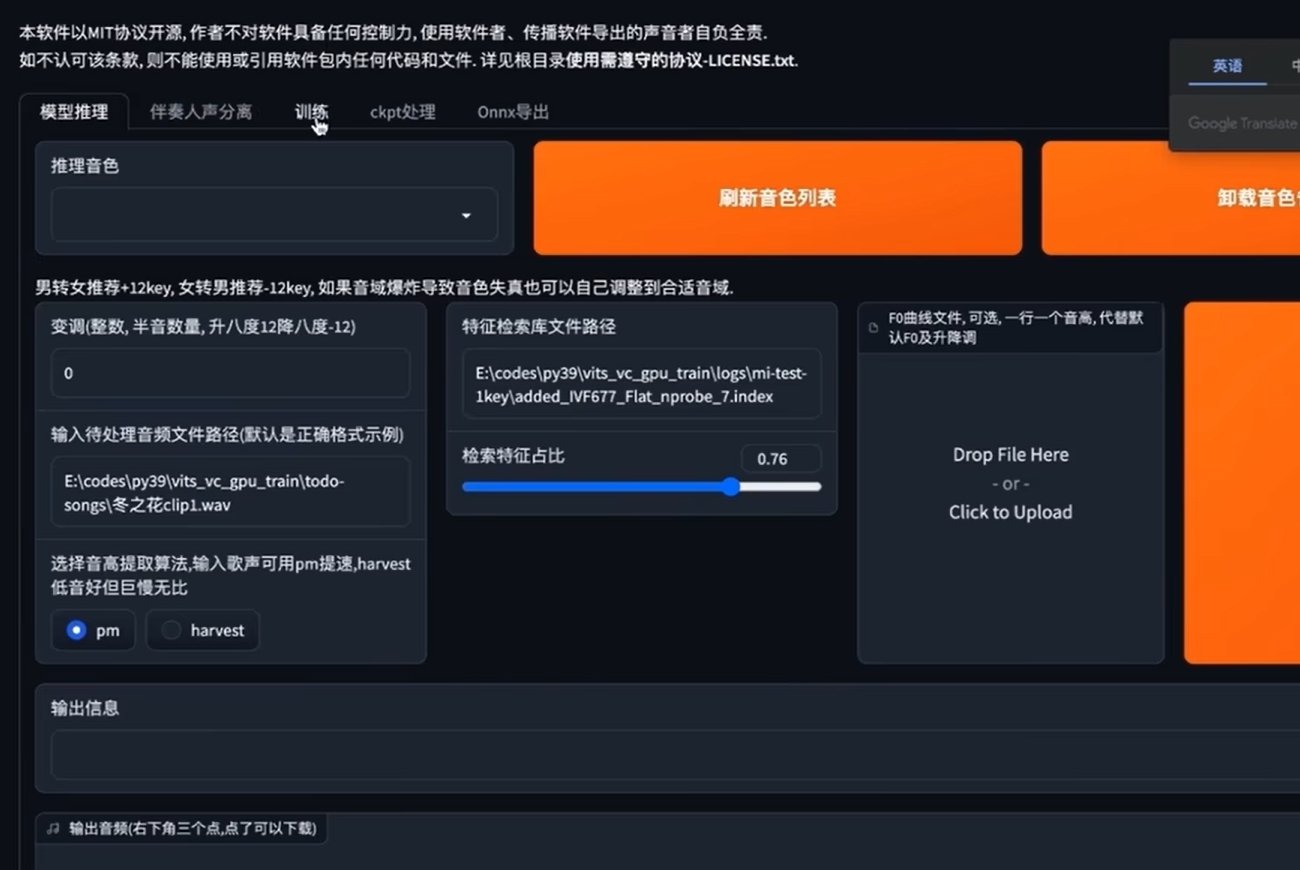
·进入后,我们首先去除伴奏
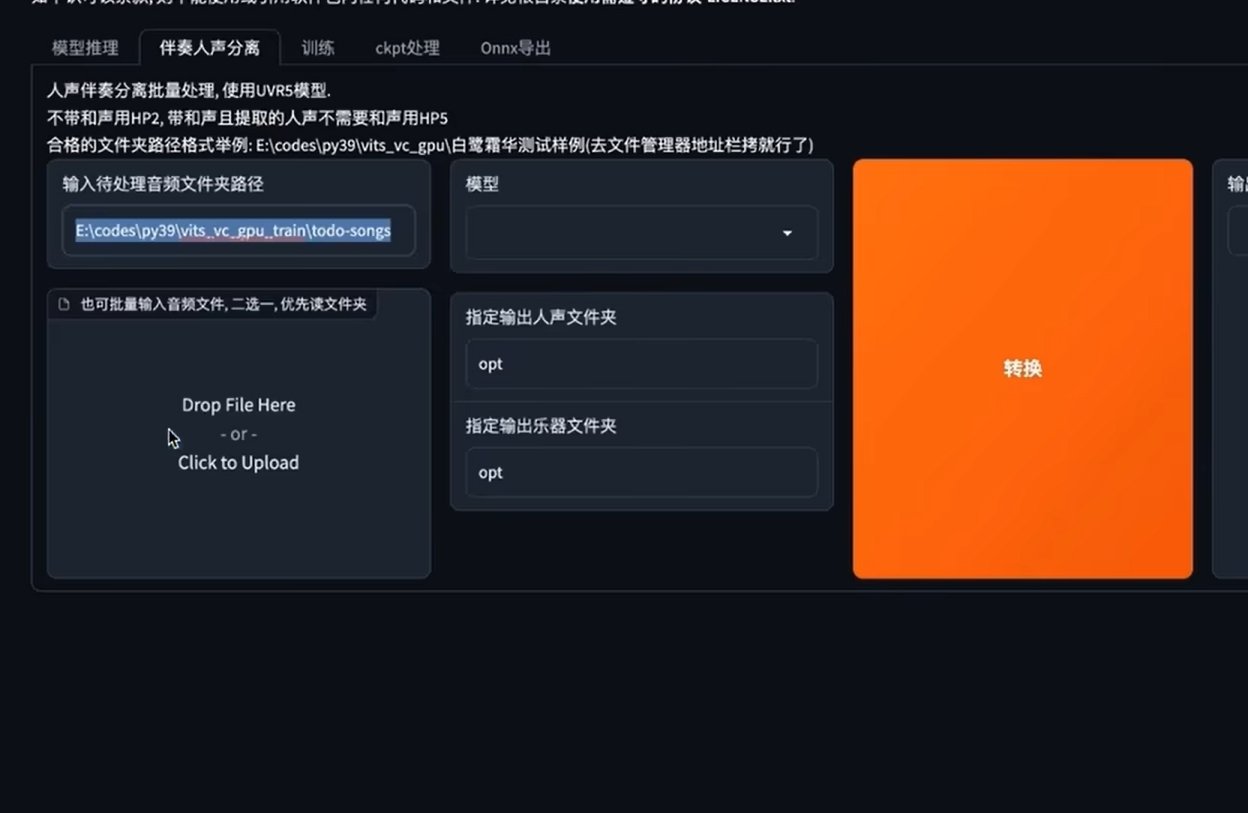
在伴奏人声分离页面,在待处理框中输入之前原始文件夹的链接。接着在分离完成后,在文件夹中找到分离好的干声数据,并复制到干声训练集的文件夹中。
·训练选项卡
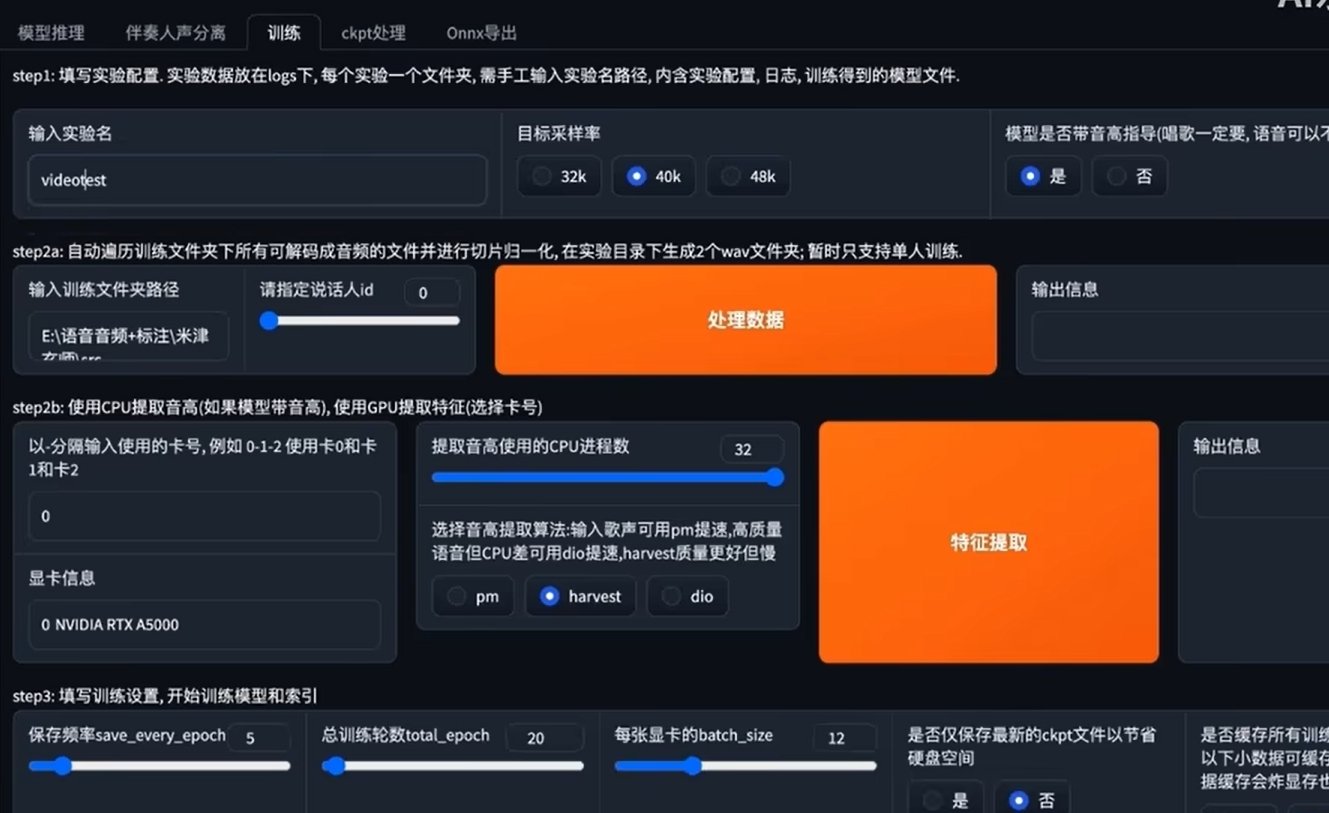
修改实验名以及输入文件夹路径,填写完成后点击一键训练。
2. 歌声转换,保存模型(云端推理)
·在推理音色处点击刷新,选择刚才训练完成的声音
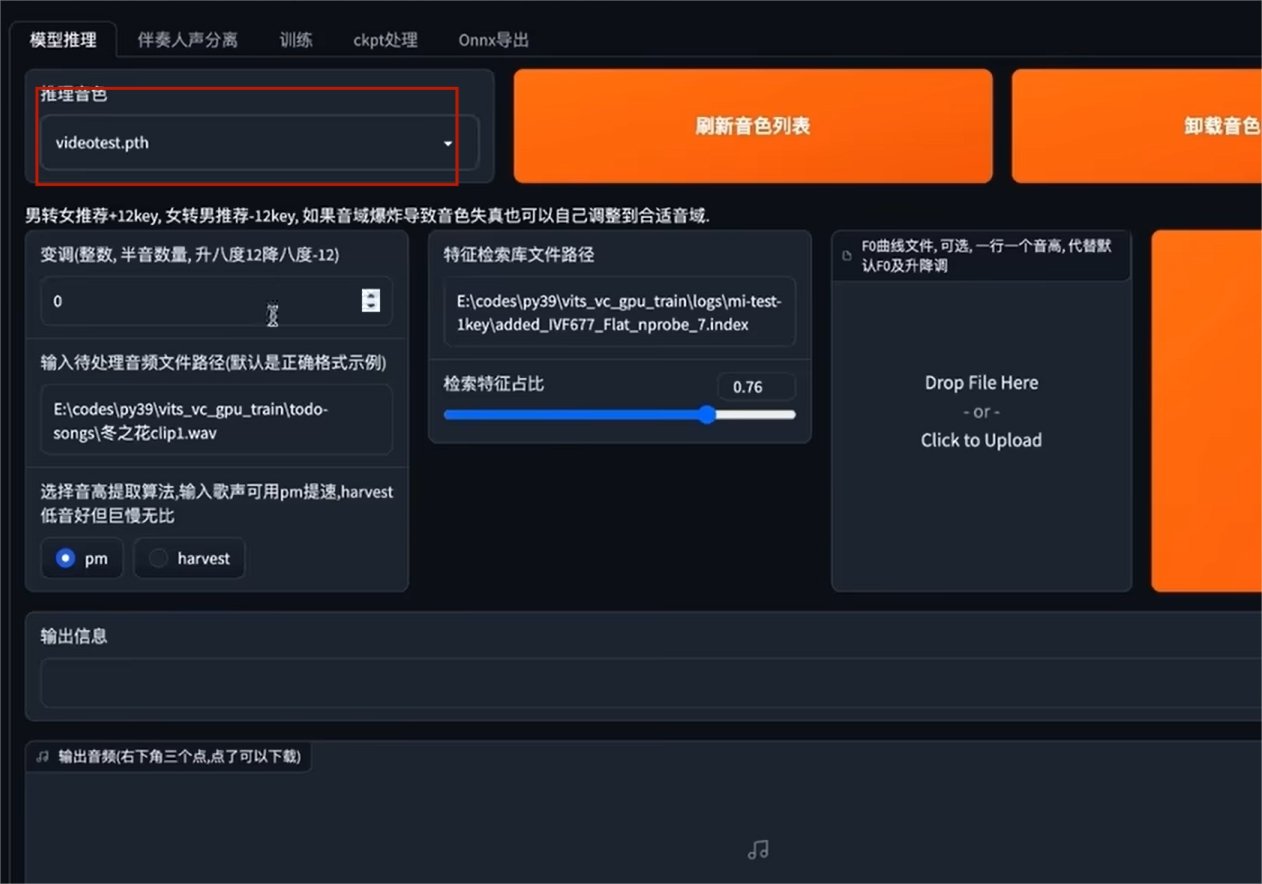
·输入变声前的音频文件路径
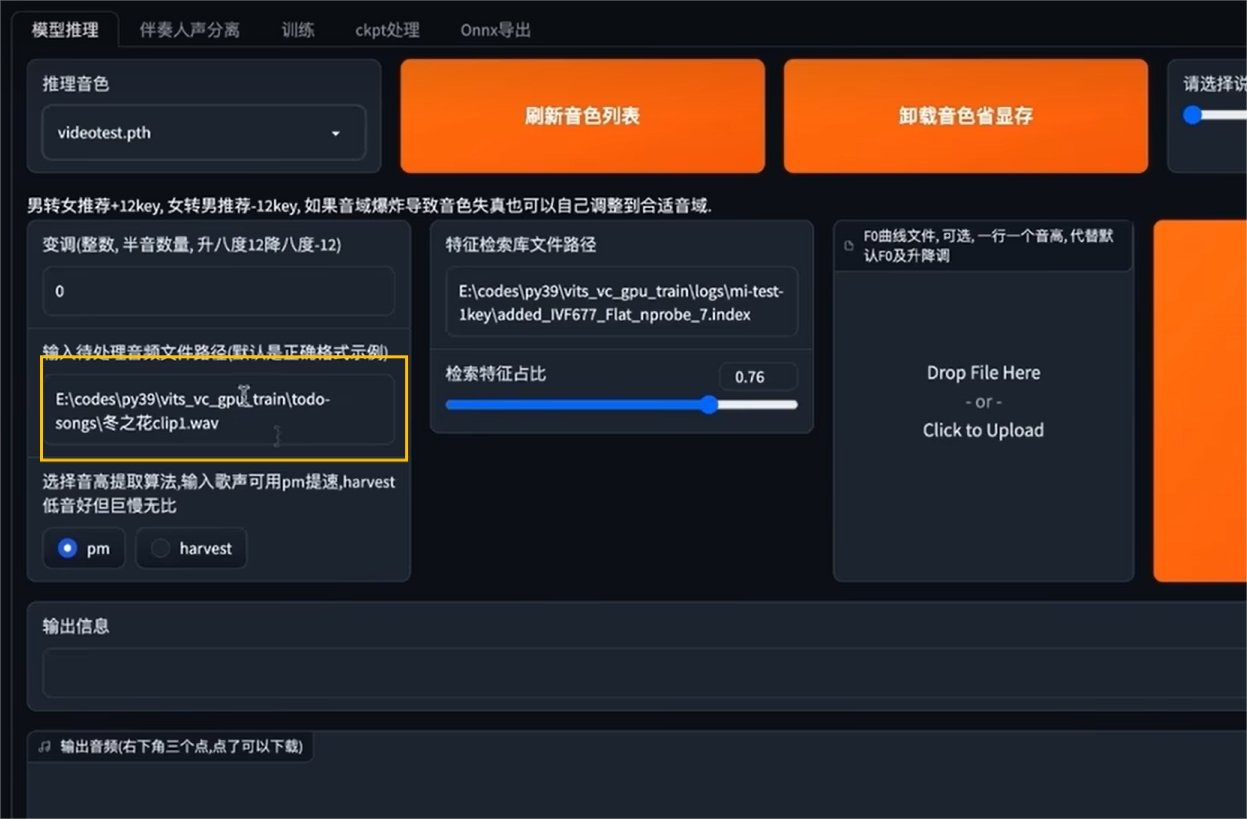
记得添加root前缀!
·在logs音乐文件夹找到特征检索库路径,复制added开头的路径
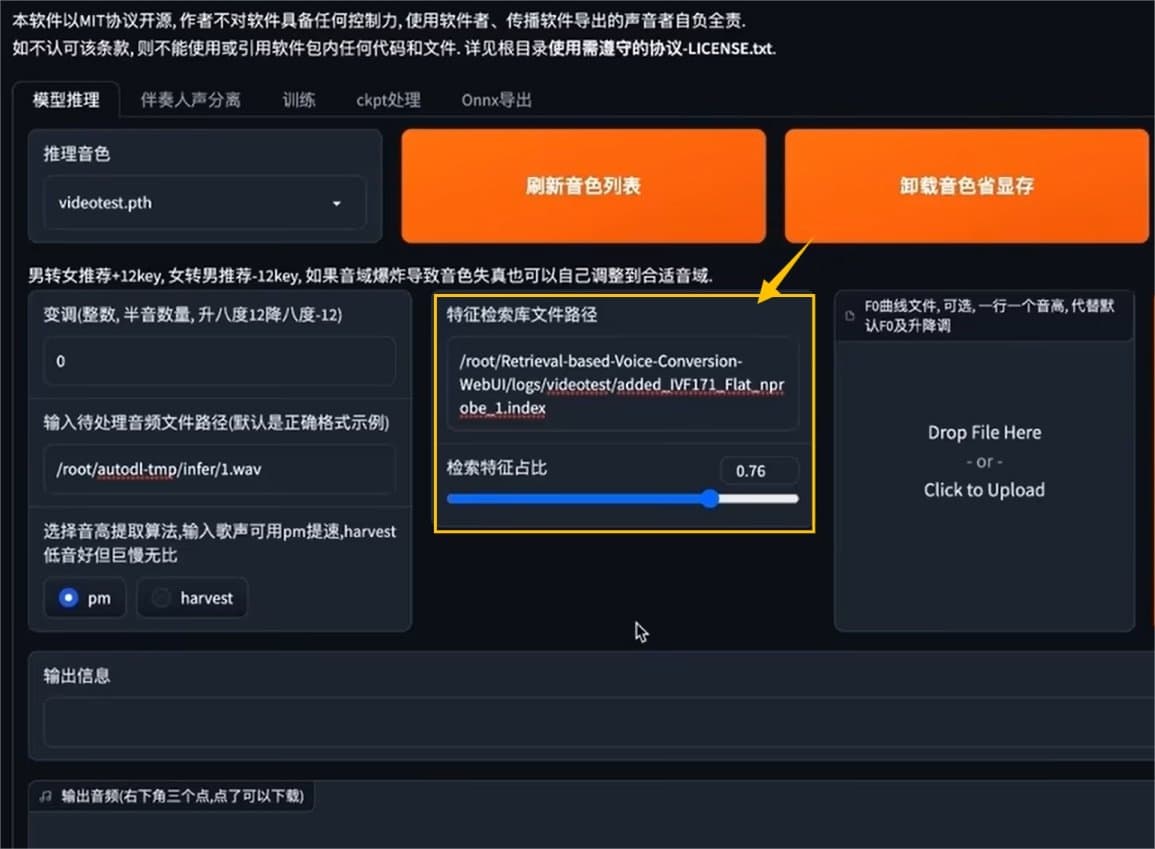
然后输入特征检索库文件路径框中。检索比例选择默认。
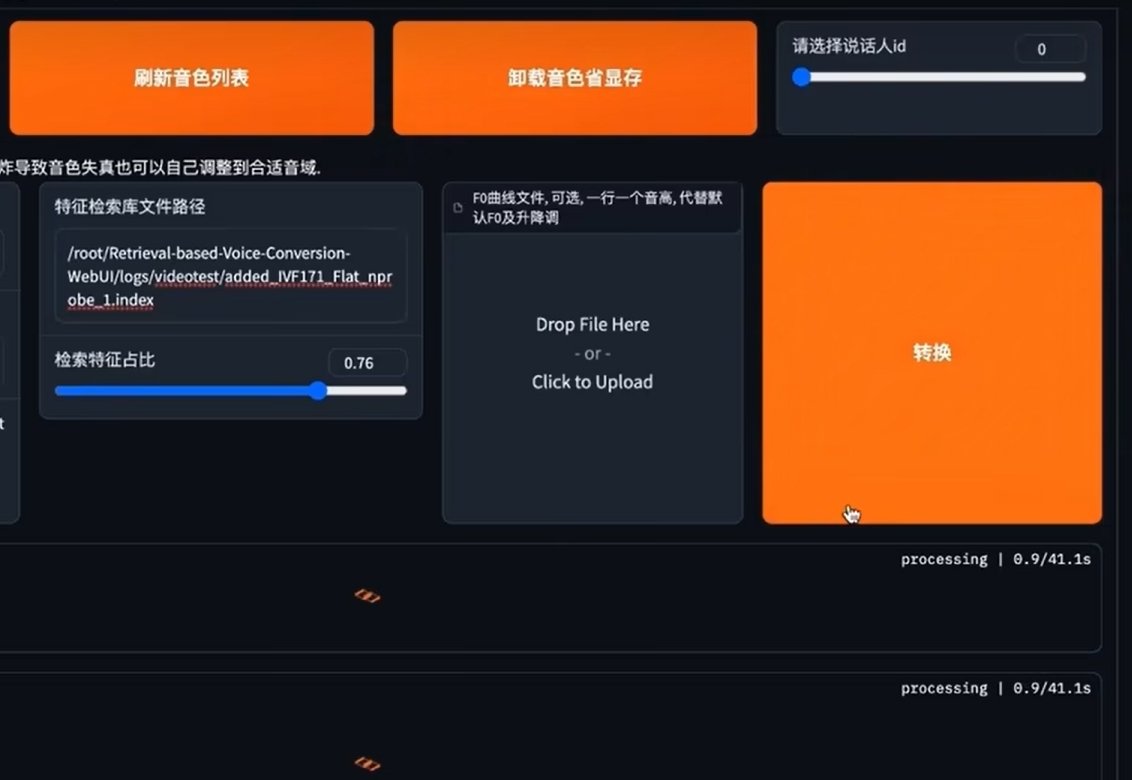
·最后点击转换,变声的音频就成功生成了
以上就是文章的全部内容,有关于AI合成变声音频的内容到这里就结束了。在当下的AI时代,越来越多的人开始使用AI技术实现心中所想。使用AI歌手来演唱喜爱的歌曲,相信这是很多人都想要实现的技术。出于对歌手的喜爱,我们利用AI来完成演唱的梦想,虽然AI歌手并不能代替真实世界的他们,但这又何尝不是一种普通人圆梦的方式呢?希望今天的内容能够对你有所帮助!
用指定的音色来点歌,合成完美变身音乐。相信小伙伴们已经开始蠢蠢欲动了。不过真正的考验还在后面,接下来,小编就来介绍如何训练云端AI,生成特定声音。
AI孙燕姿复刻指南:
1. 选择autodl显卡,准备训练(云端训练)
2. 训练模型,获得数据(云端训练)
3. 歌声转换,保存模型(云端推理)
1. 选择autodl显卡,准备训练(云端训练)
·在autodl上选择一个便宜的显卡购买
·选择最下面的镜像进入altodl RVC web UI的镜像网页
·进入网页后,点击AItodl创建容器,进入控制台
·依次点击jupyterlab、终端,并输入镜像网页提供的命令即可开启RVC的web UI
·等待控制台出现6006这行网址时,就可以通过altodl的后台点击自定义服务,用浏览器进入web了
·我们将数据上传到altodl的实例内
创建文件夹用于存放处理前的训练数据,只需要将数据从本地拖入到云端即可。
·复制该文件的路径,进入web UI
·进入后,我们首先去除伴奏
在伴奏人声分离页面,在待处理框中输入之前原始文件夹的链接。接着在分离完成后,在文件夹中找到分离好的干声数据,并复制到干声训练集的文件夹中。
·训练选项卡
修改实验名以及输入文件夹路径,填写完成后点击一键训练。
2. 歌声转换,保存模型(云端推理)
·在推理音色处点击刷新,选择刚才训练完成的声音
·输入变声前的音频文件路径
记得添加root前缀!
·在logs音乐文件夹找到特征检索库路径,复制added开头的路径
然后输入特征检索库文件路径框中。检索比例选择默认。
·最后点击转换,变声的音频就成功生成了
以上就是文章的全部内容,有关于AI合成变声音频的内容到这里就结束了。在当下的AI时代,越来越多的人开始使用AI技术实现心中所想。使用AI歌手来演唱喜爱的歌曲,相信这是很多人都想要实现的技术。出于对歌手的喜爱,我们利用AI来完成演唱的梦想,虽然AI歌手并不能代替真实世界的他们,但这又何尝不是一种普通人圆梦的方式呢?希望今天的内容能够对你有所帮助!