AI教程
视频换脸教程之用AI轻松换脸
- 2023-07-01
- Blue Sky
- 网络
如何使用AI换脸技术?相信这是很多人在看到B站上恶搞视频的第一反应。当然,如果只是处理一张照片,那么处理起来并不会很难,但如果要剪一段AI换脸后的视频呢?那又该怎么做呢?事实上,AI换脸的视频和图片的原理大致是一样的,想要以假乱真,就需要AI+造假,产生深度造假。不过AI换脸对电脑的配置要求有一点高,但最新版本我试了一下,在win10/11电脑上会有无法训练的问题,因此还是推荐使用文章的版本。
首先,让我们一起来看看AI换脸技术后的原理到底是什么?
技术原理概要:Deepfakes,一种混合“深度学习”和“造假” 的合成技术 ,其中一人的现有图像或视频被替换为其他人的肖像。Deepfakes利用了机器学习和人工智能中的强大技术来生成具有极高欺骗力的视觉和音频内容。用于创建的主要机器学习方法是基于深度学习的训练生成神经网络,如生成对抗网络GAN。
按照维基的资料,Deepfakes这个词起源于2017年底,来自Reddit用户分享了他们创建的“深度造假”产品。2018年1月,启动了名为FakeApp的桌面应用程序。此应用程序使用户可以轻松创建和共享彼此交换脸部的视频。截至2019年,FakeApp已被Faceswap和基于命令行的DeepFaceLab等开源替代产品所取代。较大的公司也开始使用Deepfake。
本文介绍使用DeepFaceLab这款开源产品,它基于python和tensorflow。
说明,基于本文掌握的内容不得用于非法违法目的以及违背道德的行为以及用于商业利益,否则本人概不负责。
开始前,需要在网页上获取下载地址,并进行安装(想要我文章版本链接的,私聊我,人多的话那回不过来!记得赞赞一下嘛!)。
这里要说下,使用DeepFaceLab最好需要足够好的电脑配置,因为AI深度训练的过程基于cpu以及gpu,显卡性能越好意味着其速度越快效果越好。但这不是绝对,如果有足够的耐心也是能够合成出一定效果的,一切都只是娱乐嘛。(ps:我写本文时用到的是win7电脑,非高配置,这不重要)
安装完毕后,你会在DeepFaceLab_NVIDIA下看到类似下图的文件:
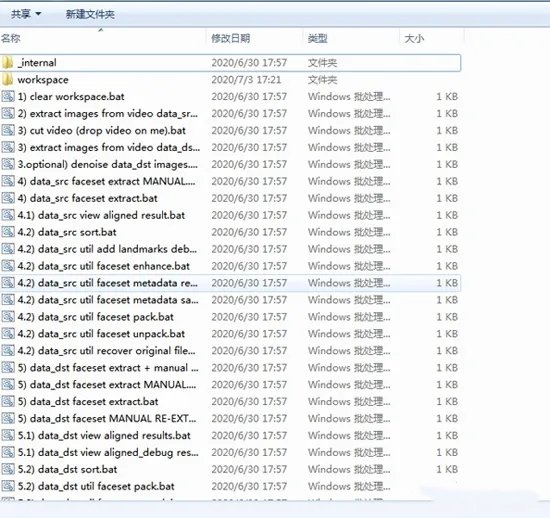
安装后会看到的一些文件
其中,workplace存放我们的视频素材以及图片。在这之前,你需要准备两个视频,源视频是你想换过去的人脸的视频(比如你自己),目标视频是被换掉的人脸的视频(比如星爷)。本文把吴孟达老师的一段“你在教我做事啊”的视频片段换成沈腾,所以使用的源视频素材是沈腾,而目标视频就是“你在教我做事啊”小片段。将源视频重命名为data_src.mp4,目标视频重命名为data_dst.mp4并放置于workplace。(确保选择的源视频素材人脸清晰、正脸、表情丰富但不要遮挡、模糊,时长不需要长)
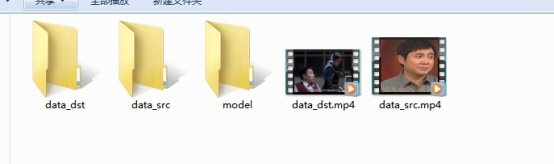
视频放置于workplace下
然后双击2) extract images from video data_src.bat,此命令将data_src视频每一帧提取为图片,回车,再回车默认选择图片格式为png。
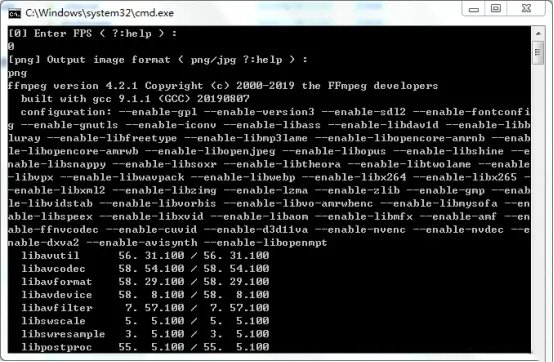
等待将data_src视频分帧
等待命令行窗口运行完毕便可关掉,以上是deepfacelab使用ffmpeg提取帧。然后,在workplace/data_src文件夹下就会看到data_src.mp4的每一帧图片,如图:
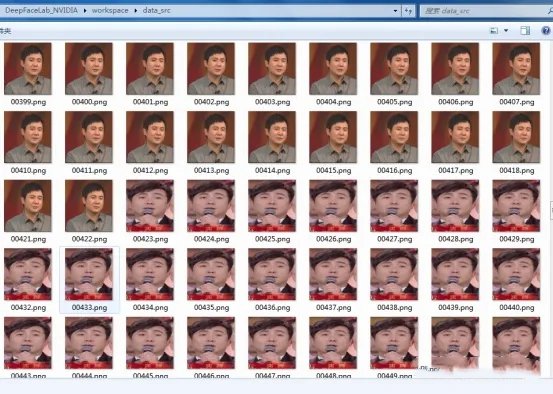
提取data_src.mp4后的每一帧
删除data_src文件夹下没有沈腾的图片以及模糊的图片。随后再执行3) extract images from video data_dst FULL FPS.bat,同样的,此命令将从data_dst.mp4中提取每一帧,执行完后在workplace/data_dst文件夹下将会看到每一帧图片。
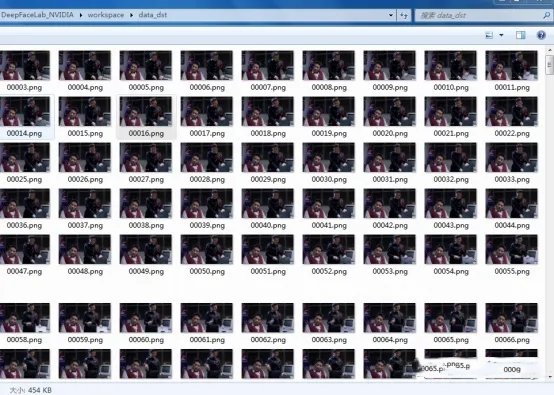
提取data_dst.mp4后的每一帧
执行4) data_src faceset extract.bat,这意味着将从data_src下的每一张图片里获取人脸。操作如下:

回车,Face type选择wf(wf=整个脸,基于情况而定,本教程基于默认选择此),Max number of faces from image默认回车键,提取最大的数量。Image Size是图片大小,默认回车512,Jpeg quality是图片质量,越高越好,默认回车90。Write debug images to aligned_debug这个选项默认回车,在data_src文件下我们可以不需要,但在操作data_dst时就需要了(程序会自动)。然后等待进程的执行,依据电脑配置,配置越高速度越快。
完成后,在data_src/aligned文件夹下会看到全部提取到的人脸,对就是沈腾的大头贴。
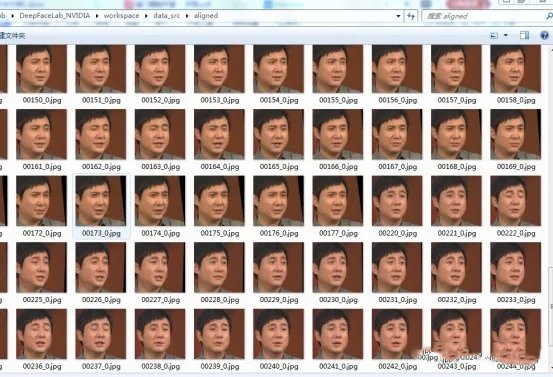
data_src/aligned下的人脸图
同样,我们在这里删除掉模糊的照片。其实前面在data_src/下删除了不合规图片,现在应该没有模糊的大头贴了。
点击5) data_dst faceset extract MANUAL.bat,从data_dst中提取人脸,这一步很重要也很繁琐!为何?我要说一下,我写本文章选的目标素材是吴孟达和叶德娴的小片段,所以视频里存在两个不同的脸。如果你的目标视频只单独存在一个人,使用data_dst faceset extract.bat可以快速的直接提取(所以并不需要此步骤的手动绘制)。而本情况一张图片里同时出现多脸,所以要选择data_dst faceset extract MANUAL.bat,随后会跳出选取窗口,需要手动提取,如下图。
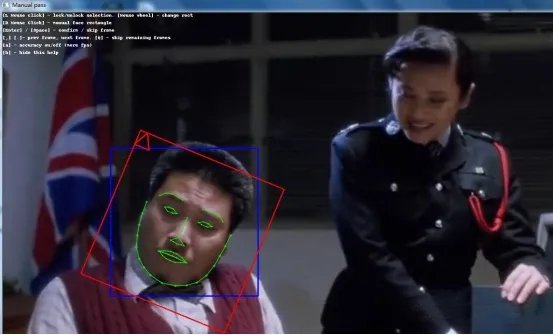
这是第一帧的图片,我们只想用沈腾的脸替换掉吴孟达老师的脸,因此用鼠标抓取。轻轻移动鼠标,程序会根据当前区域而绘制轮廓图,可以滚动滚轴放大缩小,左键锁定右键解锁,按回车确定,意味着每一张图片都需要这样,不过可以连续按住回车,当脸部大幅度变动时再重新调整。
此步骤执行完后,data_dst目录下将会出现aligned和aligned_debug两个目录。前者是吴孟达老师的大头图,后者是绘制的脸部轮廓原型。
最后到了关键一步了,就是训练模型,利用AI算法不断训练。
Deepfacelab提供了两种训练方式:quick96和SAEHD。如何选择?若你的显卡显存低于6gb,建议使用前者,而saehd是更高清晰度的模型,用于具有至少6GB显存的GPU。两种模型都可以产生良好的效果,但显然SAEHD功能更强大,因此面向非新手。为什么要训练模型?因为我们要给AI学习的这些素材,AI通过算法识别A和B两者的脸部,然后根据前者脸部的特征学会面部表情,以及如何换向另一个的脸。训练就是AI学习两个脸部的过程。
本文选择使用quick96。执行6) train Quick96.bat,第一次训练时会让你命名此模型的名字,然后就会开始训练。
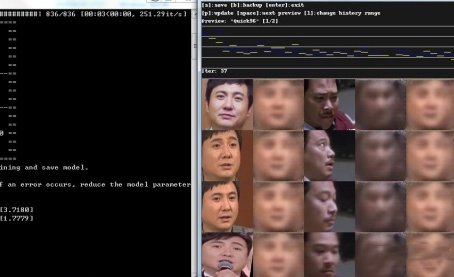
刚开始训练时
随后将弹出预览图,会看到五列脸。靠左是学习沈腾老师的脸部,靠右是吴孟达老师的,最后一列是替换之后的模样。刚开始十分模糊,随着时间的深入(根据时长以及你的计算机性能),模型将会越来越清晰。按p是更新,按s保存当前模型进度,回车关闭。模型训练需要很长的时间,如果基本上是正面的脸部视频,最好也不要低于6小时,而想要制作出精良的换脸视频,需要你的技术以及模型的时长了,甚至超过72小时都是可以的。因为模型可以随时进行训练,因此关闭之后可以再次执行train Quick96.bat。训练一段时间之后,预览图就为变得清晰:
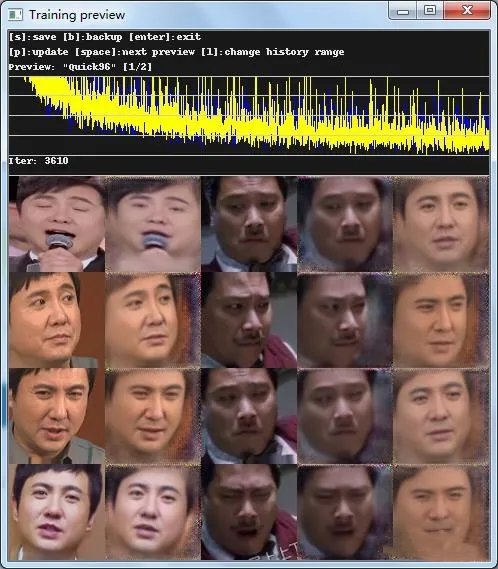
训练一段后
当你觉得不需要再训练时,可以做最后一步了。执行7) merge Quick96.bat,开始调整合并你的模型。提示Use interactive merger时按y进入交互选项界面,如图:
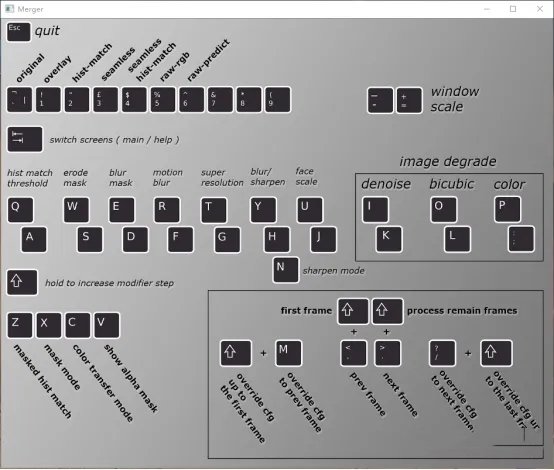
interactive窗口的配置提示
Tab键切换面板(帮助/当前帧预览),你需要按tab切换到预览窗口才能点击按钮。+和-选择窗口大小。按c是color transfer mode,更改脸部传输颜色的模式,顶部1-6数字键是更换脸部模型,u和j调整脸部覆盖的大小,n更改sharpen锐化模式,y和h调整模糊效果,w和s调整脸部遮罩的范围,e和d模糊遮罩程度,还有其他选项,这些都依据自己想要的效果不断混合调整,因此需要耐心以及熟练度。<和>步入上下帧,shfit+<返回第一帧,每完成当前帧,进入下一帧时就需要重新调整选项来达到适合的效果,你肯定要问这一帧帧得弄到猴年马月?所以若脸部没有较大波动,可以直接按/键覆盖当前选项到下一帧,若需要一次性全部覆盖,可按shift+>覆盖到最后一帧。当所有的帧都配置完毕时,可按shift+>执行Meger,可在控制窗口查看进度。
以下是某一帧类似的效果(为了写文章,效果先凑合吧):

进行调整的某一帧
下图是执行Meger的进度,当交互界面的选项更新时,命令窗口会更新选项信息。若在交互界面按了按钮卡住不动时,通常是发生错误了,可在命令窗口看到python的错误日志(遇到此情况,则需要关闭重来)。
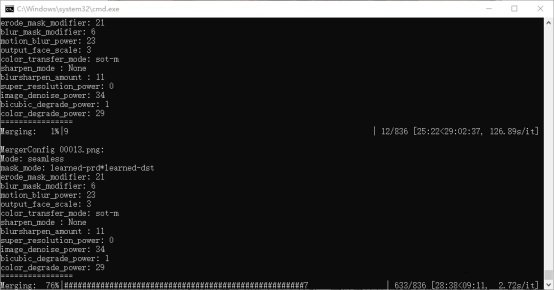
执行最终的合并时
当前操作执行完毕后,在data_dst下多出了两个文件夹merged以及merged_mask,前者是用于合成最终视频的已换脸的图片,后者是遮罩图。好的,我们执行本文教程的最后一步8) merged to mp4.bat,意味着将诞生最终的换脸视频,进程执行完毕后,在workspace目录下会看到result.mp4这个文件。最终的视频效果就不在蚊帐里进行展示了,大家可以尽情想象,或者像小编一样进行一次大胆的尝试,毕竟这只是一次娱乐,不是吗?
如果你设置得不太好以及训练太短了,效果都会不尽人意,可以重复第7步重新调整。好,来欣赏最终的换脸视频吧。
沈腾:“你在教我做事啊?”
(建议视频最好正脸,效果会更好)
首先,让我们一起来看看AI换脸技术后的原理到底是什么?
技术原理概要:Deepfakes,一种混合“深度学习”和“造假” 的合成技术 ,其中一人的现有图像或视频被替换为其他人的肖像。Deepfakes利用了机器学习和人工智能中的强大技术来生成具有极高欺骗力的视觉和音频内容。用于创建的主要机器学习方法是基于深度学习的训练生成神经网络,如生成对抗网络GAN。
按照维基的资料,Deepfakes这个词起源于2017年底,来自Reddit用户分享了他们创建的“深度造假”产品。2018年1月,启动了名为FakeApp的桌面应用程序。此应用程序使用户可以轻松创建和共享彼此交换脸部的视频。截至2019年,FakeApp已被Faceswap和基于命令行的DeepFaceLab等开源替代产品所取代。较大的公司也开始使用Deepfake。
本文介绍使用DeepFaceLab这款开源产品,它基于python和tensorflow。
说明,基于本文掌握的内容不得用于非法违法目的以及违背道德的行为以及用于商业利益,否则本人概不负责。
开始前,需要在网页上获取下载地址,并进行安装(想要我文章版本链接的,私聊我,人多的话那回不过来!记得赞赞一下嘛!)。
这里要说下,使用DeepFaceLab最好需要足够好的电脑配置,因为AI深度训练的过程基于cpu以及gpu,显卡性能越好意味着其速度越快效果越好。但这不是绝对,如果有足够的耐心也是能够合成出一定效果的,一切都只是娱乐嘛。(ps:我写本文时用到的是win7电脑,非高配置,这不重要)
安装完毕后,你会在DeepFaceLab_NVIDIA下看到类似下图的文件:
安装后会看到的一些文件
其中,workplace存放我们的视频素材以及图片。在这之前,你需要准备两个视频,源视频是你想换过去的人脸的视频(比如你自己),目标视频是被换掉的人脸的视频(比如星爷)。本文把吴孟达老师的一段“你在教我做事啊”的视频片段换成沈腾,所以使用的源视频素材是沈腾,而目标视频就是“你在教我做事啊”小片段。将源视频重命名为data_src.mp4,目标视频重命名为data_dst.mp4并放置于workplace。(确保选择的源视频素材人脸清晰、正脸、表情丰富但不要遮挡、模糊,时长不需要长)
视频放置于workplace下
然后双击2) extract images from video data_src.bat,此命令将data_src视频每一帧提取为图片,回车,再回车默认选择图片格式为png。
等待将data_src视频分帧
等待命令行窗口运行完毕便可关掉,以上是deepfacelab使用ffmpeg提取帧。然后,在workplace/data_src文件夹下就会看到data_src.mp4的每一帧图片,如图:
提取data_src.mp4后的每一帧
删除data_src文件夹下没有沈腾的图片以及模糊的图片。随后再执行3) extract images from video data_dst FULL FPS.bat,同样的,此命令将从data_dst.mp4中提取每一帧,执行完后在workplace/data_dst文件夹下将会看到每一帧图片。
提取data_dst.mp4后的每一帧
执行4) data_src faceset extract.bat,这意味着将从data_src下的每一张图片里获取人脸。操作如下:
回车,Face type选择wf(wf=整个脸,基于情况而定,本教程基于默认选择此),Max number of faces from image默认回车键,提取最大的数量。Image Size是图片大小,默认回车512,Jpeg quality是图片质量,越高越好,默认回车90。Write debug images to aligned_debug这个选项默认回车,在data_src文件下我们可以不需要,但在操作data_dst时就需要了(程序会自动)。然后等待进程的执行,依据电脑配置,配置越高速度越快。
完成后,在data_src/aligned文件夹下会看到全部提取到的人脸,对就是沈腾的大头贴。
data_src/aligned下的人脸图
同样,我们在这里删除掉模糊的照片。其实前面在data_src/下删除了不合规图片,现在应该没有模糊的大头贴了。
点击5) data_dst faceset extract MANUAL.bat,从data_dst中提取人脸,这一步很重要也很繁琐!为何?我要说一下,我写本文章选的目标素材是吴孟达和叶德娴的小片段,所以视频里存在两个不同的脸。如果你的目标视频只单独存在一个人,使用data_dst faceset extract.bat可以快速的直接提取(所以并不需要此步骤的手动绘制)。而本情况一张图片里同时出现多脸,所以要选择data_dst faceset extract MANUAL.bat,随后会跳出选取窗口,需要手动提取,如下图。
这是第一帧的图片,我们只想用沈腾的脸替换掉吴孟达老师的脸,因此用鼠标抓取。轻轻移动鼠标,程序会根据当前区域而绘制轮廓图,可以滚动滚轴放大缩小,左键锁定右键解锁,按回车确定,意味着每一张图片都需要这样,不过可以连续按住回车,当脸部大幅度变动时再重新调整。
此步骤执行完后,data_dst目录下将会出现aligned和aligned_debug两个目录。前者是吴孟达老师的大头图,后者是绘制的脸部轮廓原型。
最后到了关键一步了,就是训练模型,利用AI算法不断训练。
Deepfacelab提供了两种训练方式:quick96和SAEHD。如何选择?若你的显卡显存低于6gb,建议使用前者,而saehd是更高清晰度的模型,用于具有至少6GB显存的GPU。两种模型都可以产生良好的效果,但显然SAEHD功能更强大,因此面向非新手。为什么要训练模型?因为我们要给AI学习的这些素材,AI通过算法识别A和B两者的脸部,然后根据前者脸部的特征学会面部表情,以及如何换向另一个的脸。训练就是AI学习两个脸部的过程。
本文选择使用quick96。执行6) train Quick96.bat,第一次训练时会让你命名此模型的名字,然后就会开始训练。
刚开始训练时
随后将弹出预览图,会看到五列脸。靠左是学习沈腾老师的脸部,靠右是吴孟达老师的,最后一列是替换之后的模样。刚开始十分模糊,随着时间的深入(根据时长以及你的计算机性能),模型将会越来越清晰。按p是更新,按s保存当前模型进度,回车关闭。模型训练需要很长的时间,如果基本上是正面的脸部视频,最好也不要低于6小时,而想要制作出精良的换脸视频,需要你的技术以及模型的时长了,甚至超过72小时都是可以的。因为模型可以随时进行训练,因此关闭之后可以再次执行train Quick96.bat。训练一段时间之后,预览图就为变得清晰:
训练一段后
当你觉得不需要再训练时,可以做最后一步了。执行7) merge Quick96.bat,开始调整合并你的模型。提示Use interactive merger时按y进入交互选项界面,如图:
interactive窗口的配置提示
Tab键切换面板(帮助/当前帧预览),你需要按tab切换到预览窗口才能点击按钮。+和-选择窗口大小。按c是color transfer mode,更改脸部传输颜色的模式,顶部1-6数字键是更换脸部模型,u和j调整脸部覆盖的大小,n更改sharpen锐化模式,y和h调整模糊效果,w和s调整脸部遮罩的范围,e和d模糊遮罩程度,还有其他选项,这些都依据自己想要的效果不断混合调整,因此需要耐心以及熟练度。<和>步入上下帧,shfit+<返回第一帧,每完成当前帧,进入下一帧时就需要重新调整选项来达到适合的效果,你肯定要问这一帧帧得弄到猴年马月?所以若脸部没有较大波动,可以直接按/键覆盖当前选项到下一帧,若需要一次性全部覆盖,可按shift+>覆盖到最后一帧。当所有的帧都配置完毕时,可按shift+>执行Meger,可在控制窗口查看进度。
以下是某一帧类似的效果(为了写文章,效果先凑合吧):
进行调整的某一帧
下图是执行Meger的进度,当交互界面的选项更新时,命令窗口会更新选项信息。若在交互界面按了按钮卡住不动时,通常是发生错误了,可在命令窗口看到python的错误日志(遇到此情况,则需要关闭重来)。
执行最终的合并时
当前操作执行完毕后,在data_dst下多出了两个文件夹merged以及merged_mask,前者是用于合成最终视频的已换脸的图片,后者是遮罩图。好的,我们执行本文教程的最后一步8) merged to mp4.bat,意味着将诞生最终的换脸视频,进程执行完毕后,在workspace目录下会看到result.mp4这个文件。最终的视频效果就不在蚊帐里进行展示了,大家可以尽情想象,或者像小编一样进行一次大胆的尝试,毕竟这只是一次娱乐,不是吗?
如果你设置得不太好以及训练太短了,效果都会不尽人意,可以重复第7步重新调整。好,来欣赏最终的换脸视频吧。
沈腾:“你在教我做事啊?”
(建议视频最好正脸,效果会更好)