AI教程
ChatGPT 的 4000 个 token 上下文不够用怎么办?
- 2023-06-30
- 陶文
- 网络
ChatGPT4发布之后,似乎解决了4000个token的上下文不能完成想要完成的对话的问题。
但事实真的是如此吗?又或者说32000个token真的就做够我们进行ChatGPT的对话和代码编写的问题吗?就算我们将32000个token扔到ChatGPT里去,似乎也还是不能解决我们的核心问题。那么应该怎么办呢?
首先其容许我介绍一下利用ChatGPT的五重境界
按照从业余到专业,分为以下5重:
【输入文字少,输出文字多】:比如说,我想写一本民国穿越小说。然后等着 ChatGPT 给你把小说吐出来。
【输入文字多,输出文字少】:比如说我给 ChatGPT 5 条评论做为例子。然后让 ChatGPT 把接下来的 3 条评论仿照前 5 条的例子做同样的分类。也就是你不是来 ChatGPT 来找内容生成的灵感的,而是把它当作一个海量信息处理的工具。这个处理规则很复杂,没法手写,只能由AI来推断。
【你帮它做好任务拆解】:但是 token 不够了。为了解决这个问题,你帮它把一个大任务提前拆解好多个小任务。然后每个小任务调用一次。最后再拼接起来。比如要做一个超大文档的摘要任务。你可以搞一个切成小块的方法,然后每次让ChatGPT只做一个块的摘要。
【接入工具】:让 ChatGPT 使用工具。也就是 ChatGPT 输出的文本实际上是给你的指令。比如说ChatGPT 说这题我不会,我想Google一下这个关键字。然后你就按照ChatGPT的指令,去Google搜索完了,再把结果做为下一次的chat喂回去。
【让ChatGPT来分解任务】:你帮它做好分解任务毕竟是一个基于规则的算法,对问题的适应性有限。如果任务分解也由ChatGPT自己来呢?
1.Launch HN: Bloop (YC S21) - Code Search with GPT-4 We get around these limitations with a two-step process. First, we use GPT-4 to generate a keyword query which is passed to a semantic search engine. This embeds the query and compares it to chunks of code in vector space (we use Qdrant as our vector DB). We’ve found that using a semantic search engine for retrieval improves recall, allowing the LLM to retrieve code that doesn’t have any textual overlap with the query but is still relevant. Second, the retrieved code snippets are ranked and inserted into a final LLM prompt. We pass this to GPT-4 and its phenomenal understanding of code does the rest.
2.基于 GPT-4 / vscode 的重构工具方案 - 知乎 这个任务可以分成两个子任务。找出需要改的代码,根据例子,把修改应用到需要改的代码上。
3.State of the Art GPT-3 Summarizer For Any Size Document or Format | Width.ai
4.How to Summarize a Large Text with GPT-3
5.从文本到图片:ChatGPT + Middle Journey
6.从图片到文本:VQA + ChatGPT
这种程度的拆解是很难scale的。比如说你想让 Bloop 在你的 codebase 上理解好已有的函数库,写一个新的 UI 来调用这些函数。这是做不到的。不过如果是用来处理一些简单的工作,这种使用方法还是很不错的。
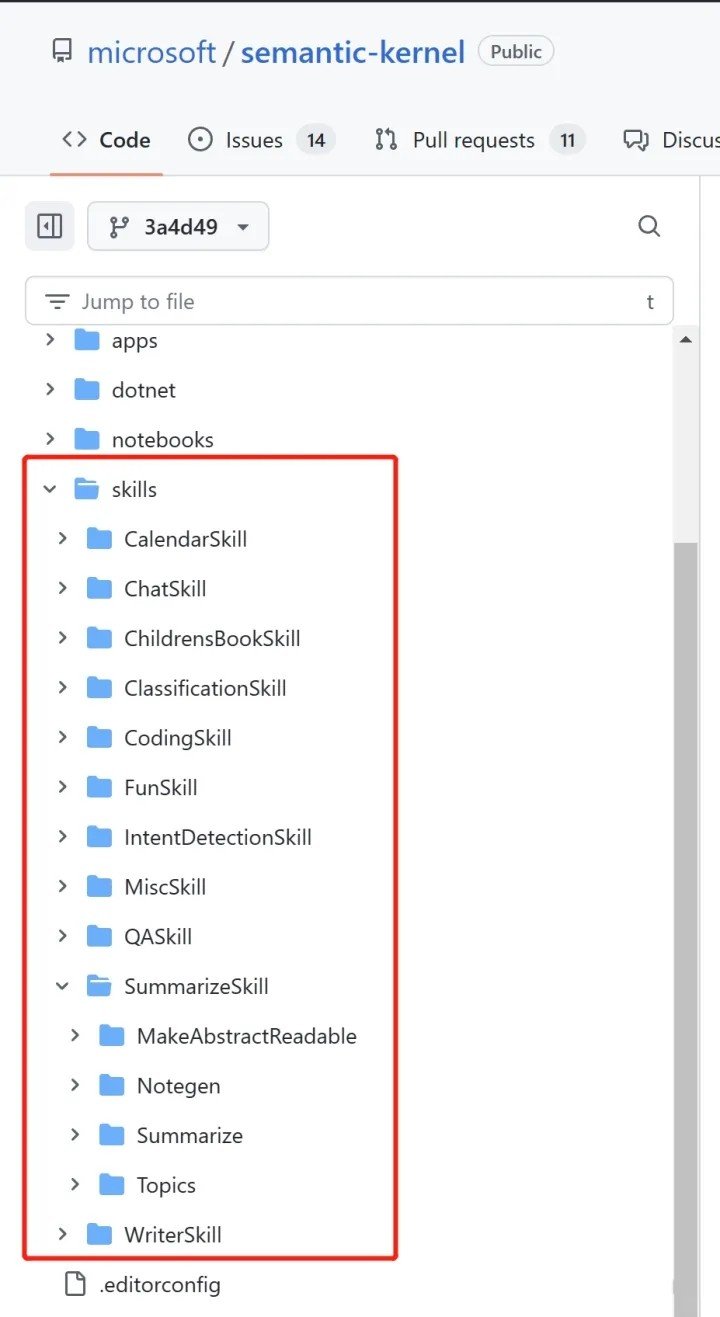
1.visual-chatgpt/visual_chatgpt.py at main · microsoft/visual-chatgpt · GitHub
2.langchain/prompt.py at master · hwchase17/langchain · GitHub
,semantic-kernel/SemanticFunctionConstants.cs at main · microsoft/semantic-kernel · GitHub
3.Langchain experiment
4.(1) Riley Goodside 在 Twitter: "From this, we learn: 1) ChatGPT is not a pure language model; prompts are prefixed with external information: “You were made by OpenAI”, plus the date. Followers of mine might find this familiar.

这些使用工具的 Prompt 都“巨长”。但是根据 通往高级智慧之路:一步到位的 GPT4 分苹果游戏 在 GPT4 里,Prompt 可以这部分完全去掉,整个长度从 40 行变成十来行。这将极大提高实用性。
能够使用的工具里有两种是最强大的,也是Prompt最难写的:
1.主动调取召回记忆的工具:比如要求从 Vector Database 里进行某个自然语言的查询
2.求助于人:就是说这个题,条件不全啊。老师你给补充一个呗
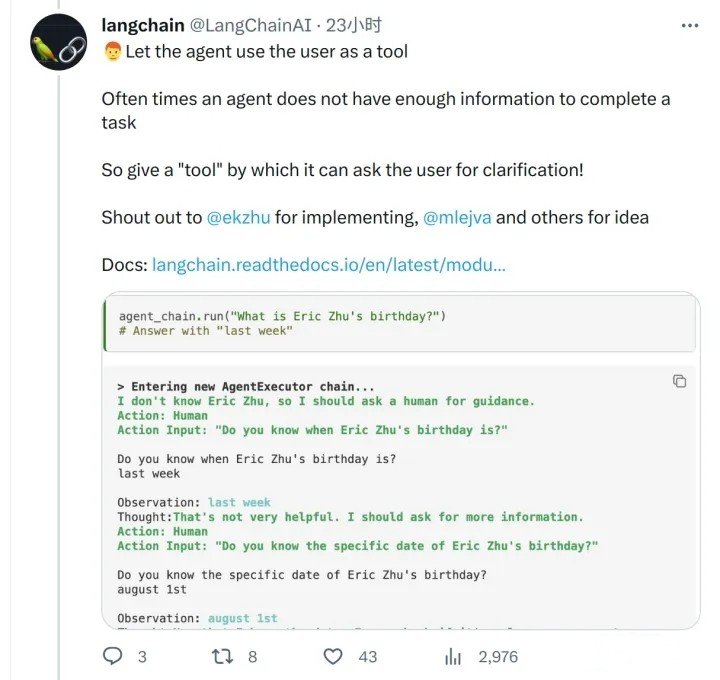
当我们手工分解任务的时候,需要把之前的任务的历史信息,发给后续的任务里做为输入。这样就很容易超过 4000 token 的长度限制。如果能把对 memory 的召回,也做为一种可选择的 tool。让 ChatGPT 对于需要召回哪些历史信息给一个自主的选择。这个选择以对 vector database 的搜索表达出来。那么似乎就可以节省大量的无意义的 context 传递。
· The surprising ease and effectiveness of AI in a loop (Interconnected)
这个路线最离谱的是 GPT-4满分第一名通过大厂模拟面试,微软154页研究刷屏:与AGI的第一次接触-36氪 GPT4在TaskRabbit平台(美国58同城)雇了个人类帮它点验证码。
Semantic Kernel 的 prompt尤其有意思:
· 先是念个咒语,生成一个 plan。plan 的步骤分成了两个类型,一个是机械的callFunction,就是函数调用
· 一个是所谓的step,也就是给chatgpt的指令。也就是由chatgpt执行的function
· 那么怎么执行这个plan呢。是用了一个改写的prompt,把这个plan做为输入,让chatgpt作一步改写,也就是消除调一个step,输出一个新的plan
· 反复改写plan,就是执行plan了
生成的 plan 长这个样子

ChatGPT 的 Plugin 也是这样工作的
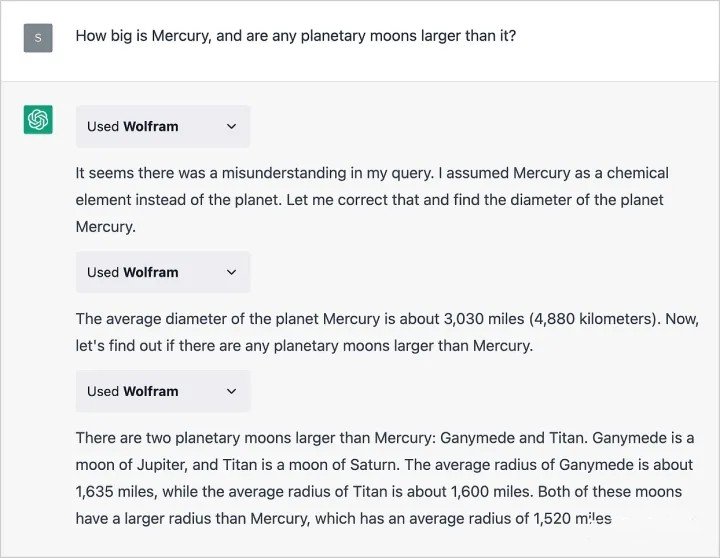
这里每一个 used wolfram,就是一次chat,然后组合多次chat,回复了最初的问题。出处 ChatGPT Gets Its “Wolfram Superpowers”!
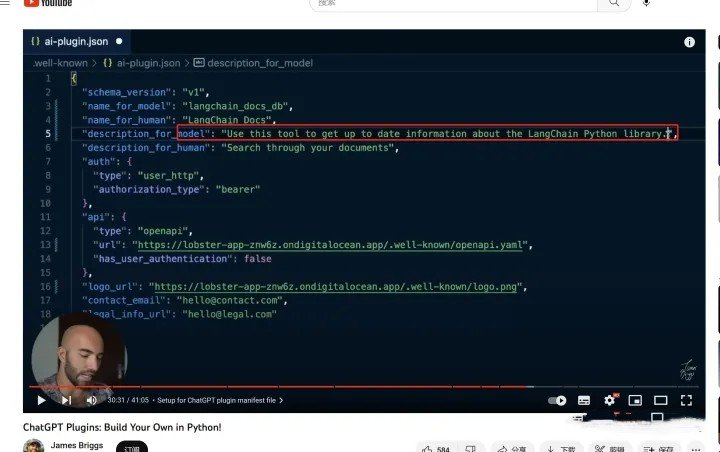
从 ChatGPT Plugins: Build Your Own in Python! - YouTube 这个视频里可以看到。ai-plugin.json 中的 description_for_model 字段就是给 ChatGPT 的 prompt。
Plugin 的 prompt 可以非常长。比如 Wolfram 这个就堪比“入职培训”了
人类在这个过程扮演的角色是 solution space 的砍枝。你给的 solution 和任务之间不能距离过远,也不能给过多的 solution。而 ChatGPT 扮演的角色就是在你砍枝过的一个相对简单的 solution space 中搜索出答案。这个比我们手工精确构造 problem solving 的每个 step 还是要轻松太多了。
Eric Evan 有句名言对我影响很深“not all of a large system will bewell designed”软件工程领域对于如何利用好印度的外包,利用好刚毕业的大学生是有很长时间的研究的,把他们限制在一个 bounded context 中工作。这和把 ChatGPT 限制在一个目标和一堆 plugin 中搜索,没啥本质区别了。很多之前软件开发中需要依靠大量人力来做的重复性工作(未来 5 年以内 AI 会多大程度影响程序员? - 知乎) 终于可以有希望被自动化了。
· RNN How the RWKV language model works | The Good Minima
· Lora 烧录长期记忆
所以经过几天的努力,我们尝试把82条我们开发者相关的信息,finetune到了这个模型当中。其实只需要T4 highRAM的colab机器,大约半个小时的训练时间(3个epoch)。从视频中可以看到模型成功记忆了我们希望他记忆的信息(也就是开发者信息,或者我简称让模型叫我爸爸)
长期记忆就是网络本身,而 RNN 在每个时间步骤上传递的 hidden state 就是对长期记忆的召回,也就是 working memory。
那么上面这些所有的努力。就是在构造一个“中期记忆”,扩展 4000 个token的限制,让ChatGPT 能帮我们完成更复杂的任务。所以,ChatGPT处理问题的能力不仅是它本身具有的供能,更多的是由我们进行引导和训练从而达到的结果。现在的ChatGPT就像是一个有着全网知识的三岁小孩,只有我们进行一步步的培训,它才能够真正发挥出人工智能的能力,助力我们更好发展。
但事实真的是如此吗?又或者说32000个token真的就做够我们进行ChatGPT的对话和代码编写的问题吗?就算我们将32000个token扔到ChatGPT里去,似乎也还是不能解决我们的核心问题。那么应该怎么办呢?
首先其容许我介绍一下利用ChatGPT的五重境界
按照从业余到专业,分为以下5重:
【输入文字少,输出文字多】:比如说,我想写一本民国穿越小说。然后等着 ChatGPT 给你把小说吐出来。
【输入文字多,输出文字少】:比如说我给 ChatGPT 5 条评论做为例子。然后让 ChatGPT 把接下来的 3 条评论仿照前 5 条的例子做同样的分类。也就是你不是来 ChatGPT 来找内容生成的灵感的,而是把它当作一个海量信息处理的工具。这个处理规则很复杂,没法手写,只能由AI来推断。
【你帮它做好任务拆解】:但是 token 不够了。为了解决这个问题,你帮它把一个大任务提前拆解好多个小任务。然后每个小任务调用一次。最后再拼接起来。比如要做一个超大文档的摘要任务。你可以搞一个切成小块的方法,然后每次让ChatGPT只做一个块的摘要。
【接入工具】:让 ChatGPT 使用工具。也就是 ChatGPT 输出的文本实际上是给你的指令。比如说ChatGPT 说这题我不会,我想Google一下这个关键字。然后你就按照ChatGPT的指令,去Google搜索完了,再把结果做为下一次的chat喂回去。
【让ChatGPT来分解任务】:你帮它做好分解任务毕竟是一个基于规则的算法,对问题的适应性有限。如果任务分解也由ChatGPT自己来呢?
输入文字多,输出文字少
基础的信息处理 Prompt Semantic Kernel 里有一箱子。就是个 Prompt “军火库”。(不过这样的处理也只能算是入门级别,并不是十分有技术含量)。如果只是日常消遣使用,那么这种使用方式还是没问题的。 你帮它做好任务拆解
这方面的资料有1.Launch HN: Bloop (YC S21) - Code Search with GPT-4 We get around these limitations with a two-step process. First, we use GPT-4 to generate a keyword query which is passed to a semantic search engine. This embeds the query and compares it to chunks of code in vector space (we use Qdrant as our vector DB). We’ve found that using a semantic search engine for retrieval improves recall, allowing the LLM to retrieve code that doesn’t have any textual overlap with the query but is still relevant. Second, the retrieved code snippets are ranked and inserted into a final LLM prompt. We pass this to GPT-4 and its phenomenal understanding of code does the rest.
2.基于 GPT-4 / vscode 的重构工具方案 - 知乎 这个任务可以分成两个子任务。找出需要改的代码,根据例子,把修改应用到需要改的代码上。
3.State of the Art GPT-3 Summarizer For Any Size Document or Format | Width.ai
4.How to Summarize a Large Text with GPT-3
5.从文本到图片:ChatGPT + Middle Journey
6.从图片到文本:VQA + ChatGPT
这种程度的拆解是很难scale的。比如说你想让 Bloop 在你的 codebase 上理解好已有的函数库,写一个新的 UI 来调用这些函数。这是做不到的。不过如果是用来处理一些简单的工作,这种使用方法还是很不错的。
接入工具
关键的难点是用什么样的 Prompt 让 ChatGPT 知道有哪些 tool 可以选择,以及怎么做选择。这方面的 Prompt 范例有1.visual-chatgpt/visual_chatgpt.py at main · microsoft/visual-chatgpt · GitHub
2.langchain/prompt.py at master · hwchase17/langchain · GitHub
,semantic-kernel/SemanticFunctionConstants.cs at main · microsoft/semantic-kernel · GitHub
3.Langchain experiment
4.(1) Riley Goodside 在 Twitter: "From this, we learn: 1) ChatGPT is not a pure language model; prompts are prefixed with external information: “You were made by OpenAI”, plus the date. Followers of mine might find this familiar.
这些使用工具的 Prompt 都“巨长”。但是根据 通往高级智慧之路:一步到位的 GPT4 分苹果游戏 在 GPT4 里,Prompt 可以这部分完全去掉,整个长度从 40 行变成十来行。这将极大提高实用性。
能够使用的工具里有两种是最强大的,也是Prompt最难写的:
1.主动调取召回记忆的工具:比如要求从 Vector Database 里进行某个自然语言的查询
2.求助于人:就是说这个题,条件不全啊。老师你给补充一个呗
当我们手工分解任务的时候,需要把之前的任务的历史信息,发给后续的任务里做为输入。这样就很容易超过 4000 token 的长度限制。如果能把对 memory 的召回,也做为一种可选择的 tool。让 ChatGPT 对于需要召回哪些历史信息给一个自主的选择。这个选择以对 vector database 的搜索表达出来。那么似乎就可以节省大量的无意义的 context 传递。
让ChatGPT来分解任务
相关资料· The surprising ease and effectiveness of AI in a loop (Interconnected)
这个路线最离谱的是 GPT-4满分第一名通过大厂模拟面试,微软154页研究刷屏:与AGI的第一次接触-36氪 GPT4在TaskRabbit平台(美国58同城)雇了个人类帮它点验证码。
Semantic Kernel 的 prompt尤其有意思:
· 先是念个咒语,生成一个 plan。plan 的步骤分成了两个类型,一个是机械的callFunction,就是函数调用
· 一个是所谓的step,也就是给chatgpt的指令。也就是由chatgpt执行的function
· 那么怎么执行这个plan呢。是用了一个改写的prompt,把这个plan做为输入,让chatgpt作一步改写,也就是消除调一个step,输出一个新的plan
· 反复改写plan,就是执行plan了
生成的 plan 长这个样子
ChatGPT 的 Plugin 也是这样工作的
这里每一个 used wolfram,就是一次chat,然后组合多次chat,回复了最初的问题。出处 ChatGPT Gets Its “Wolfram Superpowers”!
从 ChatGPT Plugins: Build Your Own in Python! - YouTube 这个视频里可以看到。ai-plugin.json 中的 description_for_model 字段就是给 ChatGPT 的 prompt。
Plugin 的 prompt 可以非常长。比如 Wolfram 这个就堪比“入职培训”了
人类在这个过程扮演的角色是 solution space 的砍枝。你给的 solution 和任务之间不能距离过远,也不能给过多的 solution。而 ChatGPT 扮演的角色就是在你砍枝过的一个相对简单的 solution space 中搜索出答案。这个比我们手工精确构造 problem solving 的每个 step 还是要轻松太多了。
Eric Evan 有句名言对我影响很深“not all of a large system will bewell designed”软件工程领域对于如何利用好印度的外包,利用好刚毕业的大学生是有很长时间的研究的,把他们限制在一个 bounded context 中工作。这和把 ChatGPT 限制在一个目标和一堆 plugin 中搜索,没啥本质区别了。很多之前软件开发中需要依靠大量人力来做的重复性工作(未来 5 年以内 AI 会多大程度影响程序员? - 知乎) 终于可以有希望被自动化了。
中期记忆
有理由相信,长期记忆和working memory是同一个东西· RNN How the RWKV language model works | The Good Minima
· Lora 烧录长期记忆
所以经过几天的努力,我们尝试把82条我们开发者相关的信息,finetune到了这个模型当中。其实只需要T4 highRAM的colab机器,大约半个小时的训练时间(3个epoch)。从视频中可以看到模型成功记忆了我们希望他记忆的信息(也就是开发者信息,或者我简称让模型叫我爸爸)
长期记忆就是网络本身,而 RNN 在每个时间步骤上传递的 hidden state 就是对长期记忆的召回,也就是 working memory。
那么上面这些所有的努力。就是在构造一个“中期记忆”,扩展 4000 个token的限制,让ChatGPT 能帮我们完成更复杂的任务。所以,ChatGPT处理问题的能力不仅是它本身具有的供能,更多的是由我们进行引导和训练从而达到的结果。现在的ChatGPT就像是一个有着全网知识的三岁小孩,只有我们进行一步步的培训,它才能够真正发挥出人工智能的能力,助力我们更好发展。