AI案例
希姆计算汹汹来袭 AI时代加速来临
- 2023-07-17
- Yuanyuan Yan
- 网络
什么是TVM?如何在 TVM 上支持 NPU?首先面对这两个问题,可能很多人都觉得有点深奥,毕竟这和ChatGPT、midjourney的使用教程介绍都不一样,今天要介绍的AI有关内容更加专业化,也更加难懂。所以,小伙伴们要做好阅读准备,相信在读完本文后你一定会在AI之路上更进一步。
首先小编来介绍一下什么是TVM
TVM是TensorFlow.js的一个插件,可以将TensorFlow.js转换为TensorFlow.TVM。TensorFlow.TVM是一个轻量级的版本,具有更快的执行速度和更好的内存管理。它可以减少一些不必要的开销,并提供更好的硬件资源利用率,适合于快速原型设计和迭代开发。同时,它还提供了一种称为“动态绑定”的技术,可以在运行时动态地为每个任务分配适当的GPU资源。
那么在TVM上支持NPU又需要怎么做呢?
DSA 编译器解决的本质问题就是不同的模型需要部署到硬件上,利用各种抽象层级的优化手段,使得模型尽量打满芯片,也就是要压缩气泡。关于怎么去调度,Halide 描述的调度三角形是这个问题的本质。
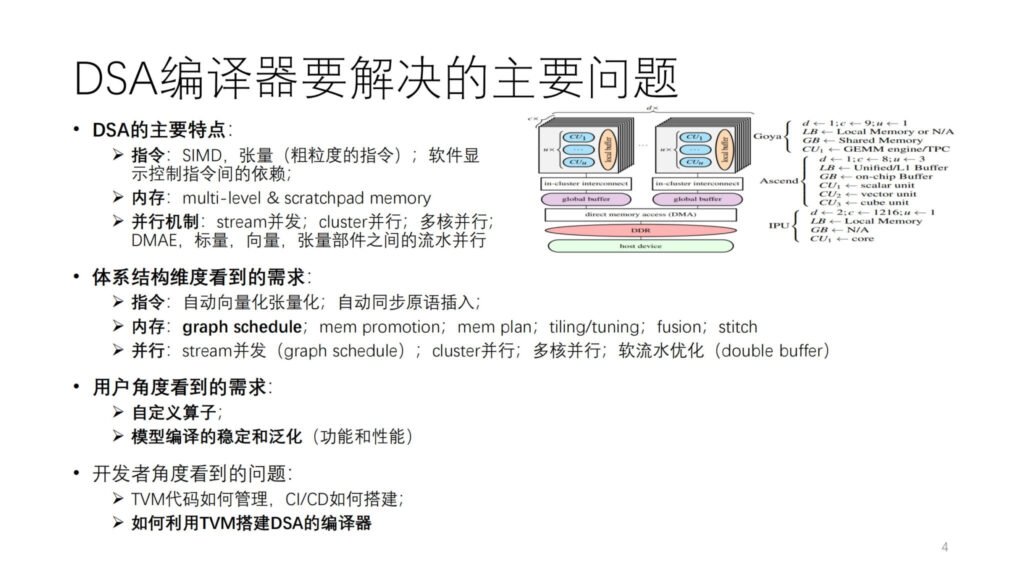
DSA 编译器要解决的主要问题是什么?首先我们抽象一个 DSA 的架构,如图所示,habana、Ascend 以及 IPU 上都是这个抽象架构的实例化。一般计算核里每个核有向量、标量以及 张量 的计算单元。从指令的操作和数据粒度来看,不少 DSA 可能倾向于使用相对粗粒度的指令,例如二维三维的向量和张量的指令,也有不少硬件使用细粒度的指令,例如一维的 SIMD 和 VLIW。指令间的依赖,有一些是通过显式的接口暴露让软件来控制,有的是硬件自己控制。内存是多级内存,大多是 scratchpad memory。并行有各种粒度和维度的并行,比如 stream 并行、cluster 并行、多核并行以及不同计算部件之间的流水并行。
要支持这样一类架构,从编译器开发者的角度看,是从上述体系 结构 几个方面对 AI 编译器提出不同的需求,这部分后面我们会展开。
从用户的角度看,首先要有一个稳定和泛化的编译器,尽量多的模型或者算子都可以编译成功,另外,用户希望编译器可以提供一个可编程的界面来进行 算法 和算子的自定义,以确保可以独立开展一些关键算法的创新工作。最后,对于类似我们这样的团队或者友商也会关注:怎么用 TVM 构建 AI 编译器,比如怎样管理自研和开源的 TVM 代码,怎么搭建一套高效 CI 等等。这就是我们今天要分享的内容,下面由我的同事来讲编译优化的部分。
希姆计算王成科:DSA 的编译优化流程
本部分为希姆计算工程师王成科现场分享。
首先介绍一下希姆编译实践的整体流程概况。
针对刚才提到的架构特性,我们基于 TVM 数据结构构建了自研的优化 pass 再加上对 TVM 的复用,组成了一个新模式实现:tensorturbo。
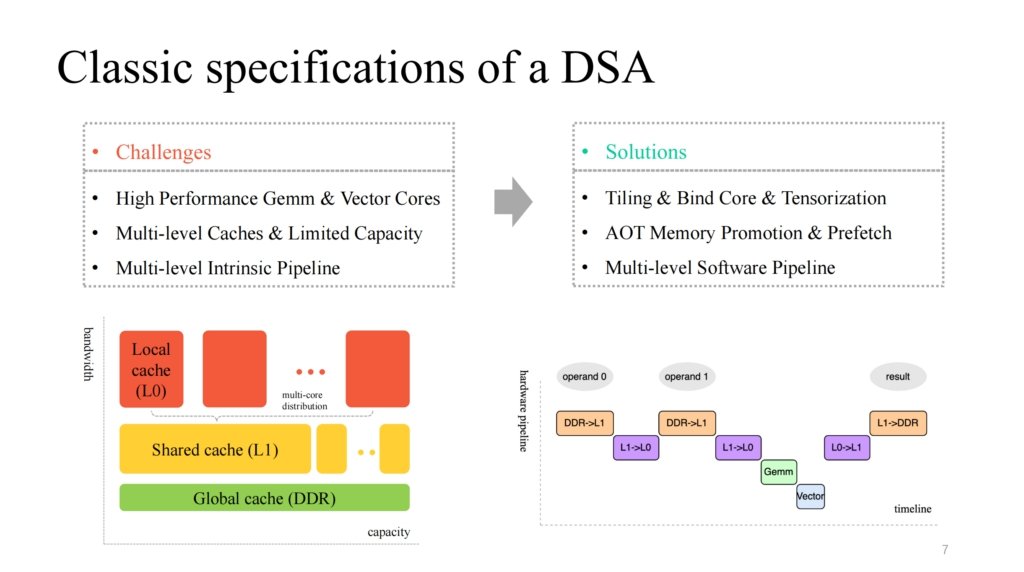
我们看到一个比较经典的 DSA 架构,一般会提供一些高效、定制矩阵以及向量层的多核计算核心,拥有一个与之相配合的多层缓存机制,同时也会提供可并行运行的多模组执行单元。相应的我们需要处理以下问题:
对数据计算进行切分、高效绑核以及定制指令的高效向量化;
精细管理有限的片上缓存,在不同的缓存等级上做相应的数据预取;
优化多模组执行的多级流水线,力求得到一个比较好的加速比。

这里红色部分(上图)显示的是整个流程里对 TVM 复用比较高的部分,在 relay 上实现的图层相关比较通用的优化可以直接复用,另外复用程度比较高的是基于 TensorIR 和 custom LLIR 的算子实现部分。像我们刚才提到的跟硬件特性相关的定制优化,则需要更多自研工作。
首先我们来看在图层上自研的一项工作。

关注最左边这张比较典型的计算流图,可以看到从上到下,整体对缓存的占用及对计算的占用都在不断减少,呈现倒金字塔的状态。对于前半部分,模型规模较大时,我们需要着重解决片上缓存驻留的问题;而后半部分,在模型规模比较小的时候,需要处理计算单元利用率较低的问题。如果简单调整模型规模,比如调整 batch size ,较小的 batch size 可以得到较低的 latency ,而相应的 throughput 会有所降低;同样较大的 batch size 会导致 latency 较高,但是有可能提高整体 throughput。
那么我们就可以用图调度来解决这个问题。首先,允许一个比较大的 batch size 输入,保证全程对计算的利用率比较高,然后对整图做一个存储分析,加上切分和调度策略,使得模型的前半部分结果可以更好地缓存在片上,同时实现计算核心利用率较高的结果。实践来看整体可以实现 latency 和 throughput 都表现较好结果(详细可以关注 OSDI 23 希姆文章:Effectively Scheduling Computational Graphs of Deep Neural Networks toward Their Domain-Specific Accelerators,6 月份可获取链接查看)。
下面介绍另外一个软流水的加速工作。
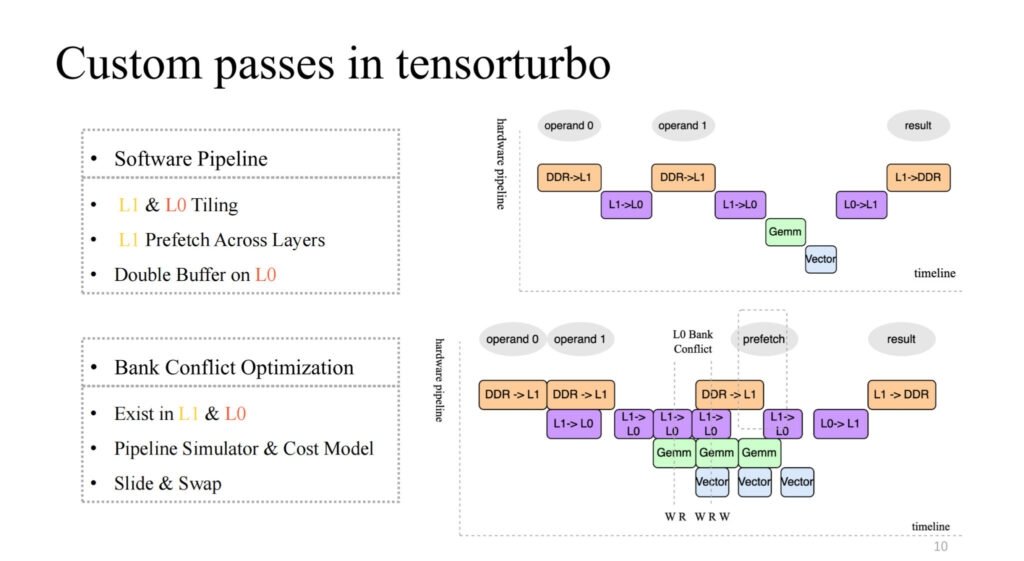
关注右上图,实现了一个比较 native 的四级流水线,但明显不是一个高效的流水线。一般高效的流水线,应该是经过几次迭代后,四个执行单元都可以同步并行起来,那么这需要做一些工作,包括 L1 及 L0 上的切分、L1 上跨层的数据预取以及 L0 层级上的 double buffer 操作。通过这些工作我们可以实现像右下图所展示的,加速比较高的流水线。
由此,也会引入一个新的问题,比如当多个执行单元对缓存的同时读写并发数要高于当前缓存可支持的并发数时,就会产生竞争,这个问题会导致访存效率成倍下降,也就是 Bank Conflict 问题。对此,我们会在编译时静态地对流水线进行模拟,提取冲突对象,结合 cost model 对分配地址进行交换和平移,可以极大地降低该问题的影响。
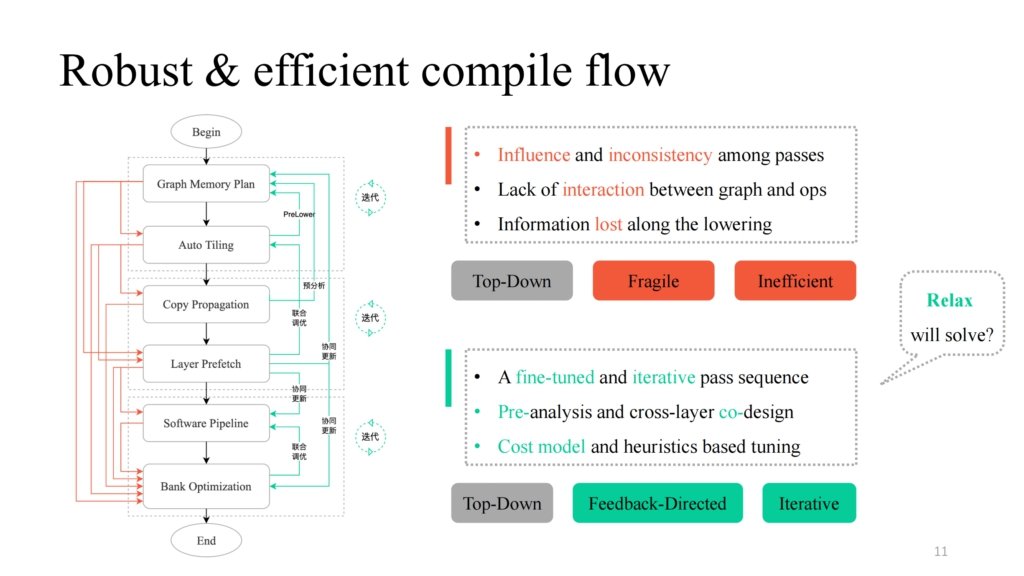
有了各种 pass 之后,可以以一个简单的 Top-Down 方式把它们组合起来,沿着左图中黑色流程,就得到了一个功能上可行的编译 pipeline。但是实践中发现很多问题,包括思远提到的 pass 与 pass 之间的相互影响、缺少交互逻辑,图层与算子之间缺少沟通逻辑等。可以看到左图中红色部分指示的流程,实践中发现每个路径或者它们的组合都会导致编译失败。如何让其鲁棒性更强?希姆在每个可能失败的 pass 中提供一个反馈路径,在图层和算子之间引入了交互逻辑,进行预分析、 prelower 操作,同时在重点部分引入一些迭代调优机制,最终得到一个泛化性较高且调优能力比较强的整体 pipeline 实现。
我们也留意到,上述工作中对数据结构的改造以及相关设计思想与目前 TVM Unity 设计有较多相似之处,我们也期待 Relax 能够带来更多可能性。
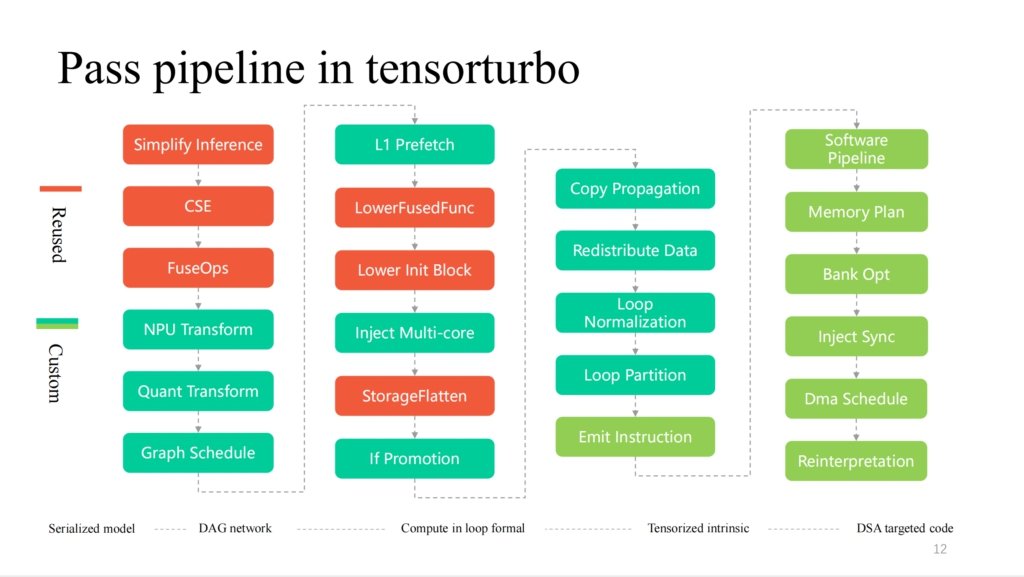
这里展示的是希姆在编译流程中更加细节的 pass,从左到右就是逐层递减的过程,其中红色部分是对 TVM 复用比较高的,越靠近硬件特性部分会有更多的定制 pass。
下面继续对其中的部分模块进行详细介绍。
希姆计算刘飞:DSA 的向量化和张量化
本部分为希姆计算工程师刘飞现场分享。
这个章节将展开介绍希姆向量化和张量化工作。从指令粒度考虑,指令粒度越粗,越接近 Tensor IR 的多层 loop 表达,所以向量化张量化难度越小,相反,指令粒度越细,难度也就越大,我们的 NPU 指令,支持一维/二维/三维的 tensor 数据计算。希姆也考虑过原生 TVM tensorize 过程,但考虑到 Compute Tensorize 对复杂表达能力有限,例如对 if condition 这种复杂表达式做 Tensorized 就比较困难,而且做 Tensorized 向量化后,无法 schedule。
另外当时 TensorIR Tensorize 在开发当中,不能满足开发需求,所以希姆提供了自己的一套指令向量化流程,我们称之为指令发射。这套流程下我们支持了大概 120 条 Tensor 指令,包括各种维度的指令等。

我们的指令流程大概分为三个模块:
发射前的优化处理。对循环轴的变换,为指令发射提供更多的发射条件和可能;
指令发射模块。分析循环的结果和信息,选择一个最优的指令生成方式;
指令发射后的模块。对指定发射处理失败之后处理,保证在 CPU 上正确执行。
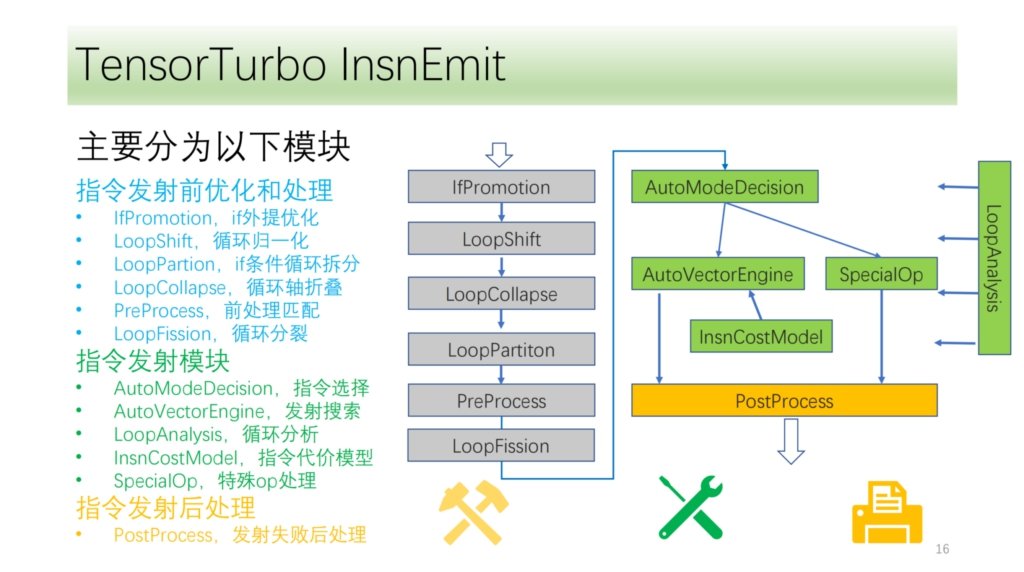
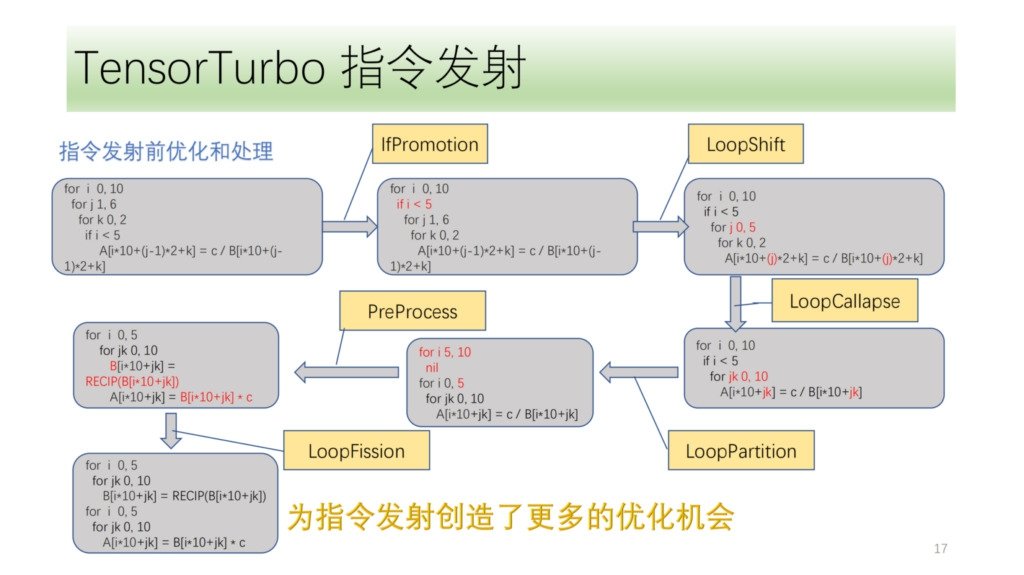
下面是指令发射前的优化和处理模块,都是由一组优化 pass 组成,其中 IfPromotion 是把阻碍循环轴发射的 if 语句尽量外提,PreProcess 是把没有对应指令的 operator 做拆分处理,LoopShift 是对循环轴边界为 归一化 ,LoopCallapse 是对连续的循环轴作尽可能的合并,LoopPartition 是做 if 相关的循环轴拆分,还有 LoopFission 是对循环内多个 store 语句的分裂。
从这个例子可以看到,起初 IR 是不能发射任何指令的,通过优化后,最后可以发射两条 Tensor 指令且所有的循环轴都能够发射指令。
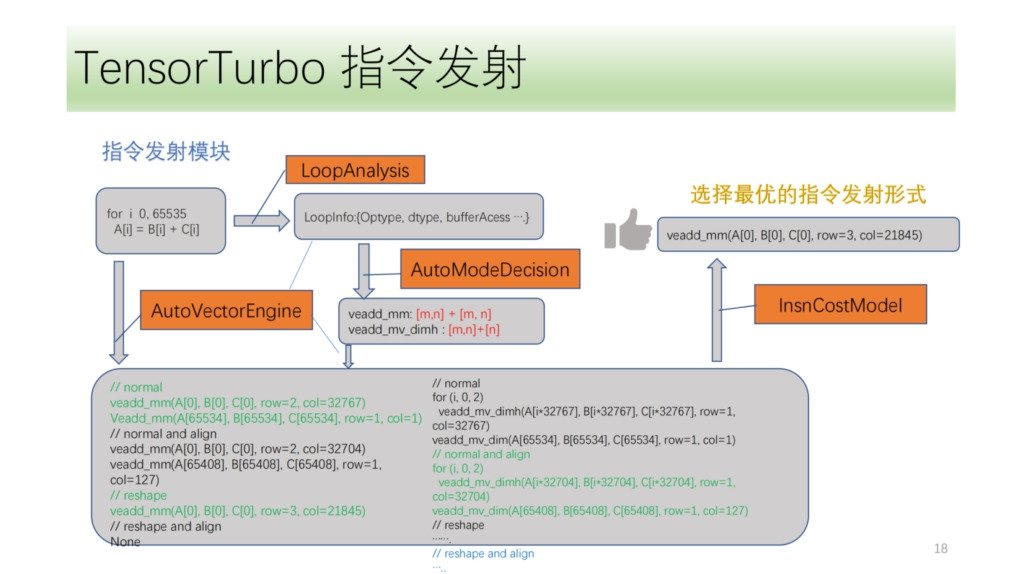
再就是指令发射模块。首先,指令发射模块会循环分析循环中的结构,从中获取 Optype、dtype、bufferAcess 等信息,有这些信息之后,指令识别会识别出来循环轴可能会发射哪几种指令。因为一种 IR 结构可能对应多种 NPU 指令,所以我们会把所有可能发射的指令都识别出来,由 VectorEngine 搜索引擎去根据指令的 alignment、reshape 等一系列信息去搜索每种指令发射的可能性,最后再由 CostModel 做计算,找到最优发射形式进行发射。
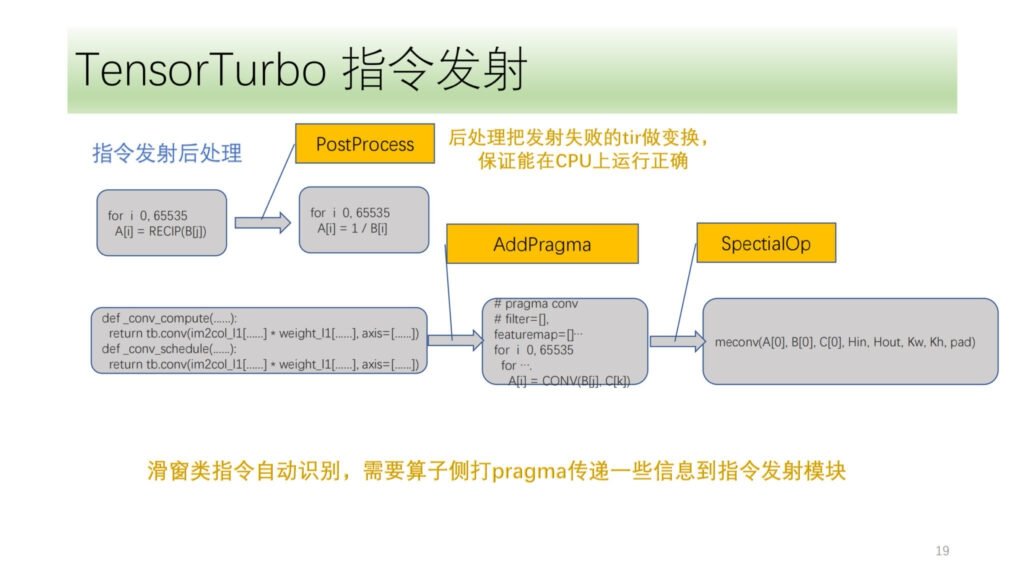
最后就是指令发射后处理模块。主要是对指令发射失败的 tir 做处理,保证其能在 CPU 上正确运行。还有一些特殊指令,希姆需要在算法前端打一些标记,指令发射模块通过这些标记加上自己的 IR 分析,正确地发射相应的指令。
以上是希姆整个 DSA 张量化和向量化的流程,我们也在一些方向上做了探索,比如微内核的方案,也是最近讨论比较热烈的方向。它的基本思想是把一个计算过程分成两层,一层用组合微内核的形式去拼接,另一种用搜索的方式去寻找,最终把两层的结果做拼接,选择一个最优结果。这样其优势是充分利用硬件资源的同时,降低搜索的复杂度,提高搜索效率。

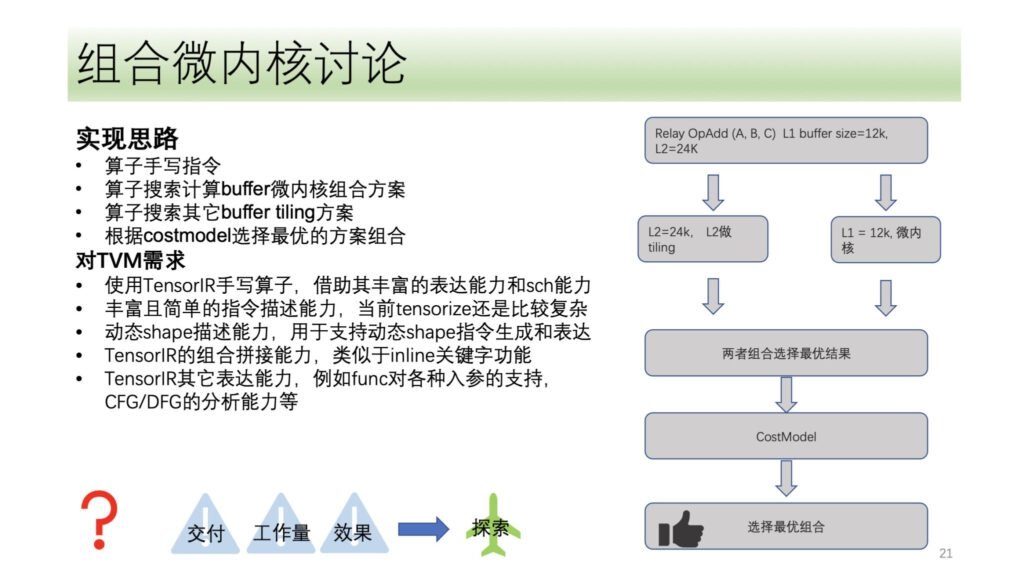
希姆也在微内核上做了相关探索,但考虑到微内核方案与现在的解决方案相比,并没有在性能等方面有较大提升,所以目前希姆在微内核方向还属于探索阶段。
希姆计算袁晟:DSA 的自定义算子
本部分为希姆计算工程师袁晟现场分享。
首先,我们知道算子开发目前碰到了四个大问题:
需要支持的神经网络算子很多,进行归类后基础算子有 100 多个;
由于硬件架构不停迭代,相应指令以及算子参与的逻辑都需要进行变更;
性能考虑。算子融合 (local memory, share memory) 以及我前边提到的图算信息传递(切分等);
算子需要开放给用户,用户只能进入软件进行自定义算子。
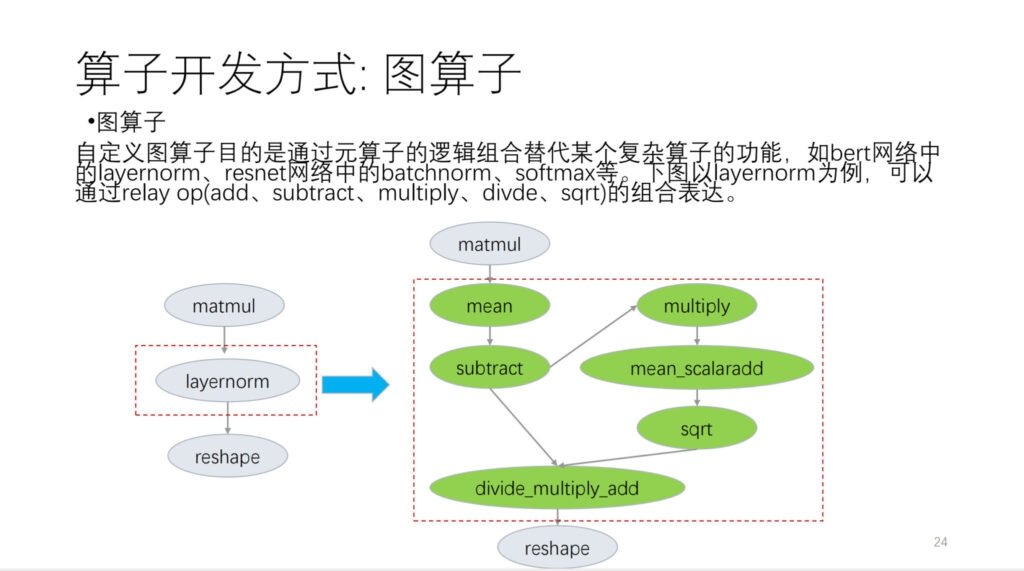
我主要分成了以下三个方面介绍。首先是图算子,图算子是基于 relay api,把它裁剪成基础的语言算子。
以下图为例:
第二是元算子,所谓的元算子是基于 TVM Topi 用 compute/schedule 描述算子算法逻辑和循环变换相关逻辑。我们在开发算子时,会发现很多算子的 schedule 是可以复用的,基于这种情况下,希姆提供了一套类似 schedule 的模板。现在,我们把算子分成很多类,基于这些类,新的算子就会大量复用 schedule 模板。
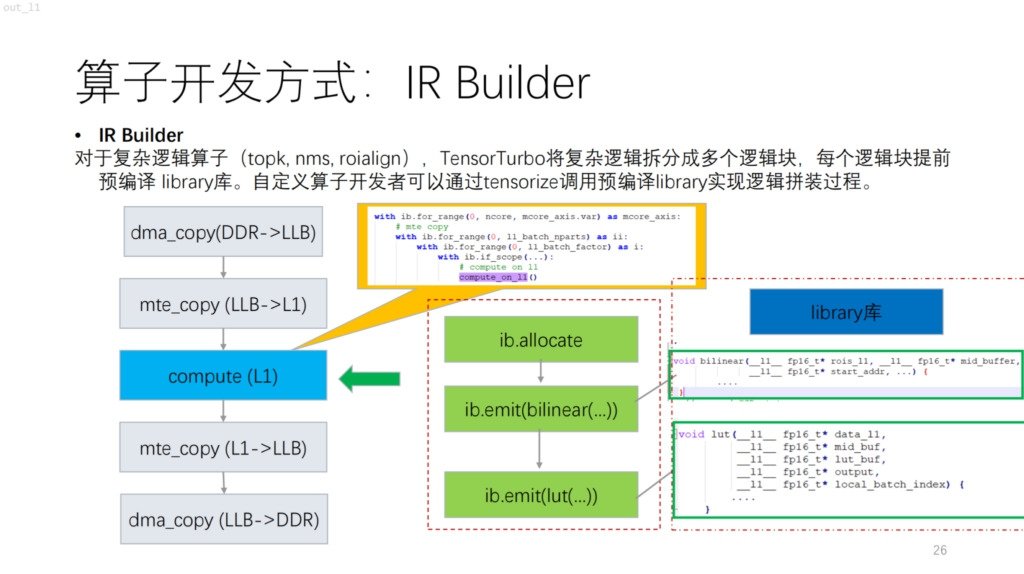
接下来是一个比较复杂的算子,基于 NPU 的情况下,大家会发现 topk、nms 等带控制流的算法,带很多标量计算,目前用 compute/schedule 很难描述,为解决这个问题,希姆提供一个类似 library 库。相当于在 library 库先编译复杂的逻辑,然后通过跟 IR Builder 结合的方式,把整个算子的逻辑输出。
接下来是算子的切分。对于 NPU,相对 GPU 和 CPU 情况下,TVM 每条指令都会操作连续内存块,同时会有 memory size 限制。同时,在这种情况下,搜索空间不大。基于这些问题,希姆提供了解决办法,首先,会有一个候选集,把可行的解题放到候选集里,其次,对可行性进行解释,主要考虑性能要求以及 NPU 指令限制,最后,会引入 cost function,其中会考虑算子特征以及可能用到的计算单元特征。
再接下来对算子开发比较有挑战性的就是融合算子。目前面临两个爆炸性问题,第一不知道如何将自己的算子和其他算子组合,第二个可以看到 NPU 里有很多 memory 层级,出现爆炸式 memory 层级的融合。希姆 LLB 会有 shared memory 和 local memory 等融合的组合,基于这种情况下,我们也提供一个自动生成框架,先根据图层给的调度信息,插入数据搬移操作,再根据 schedule 里 master op 和 salve op 提炼 schedule info,最后根据当前指令的限制等问题做一个后处理。

最后主要展示希姆支持的算子。ONNX 算子大概是 124 个,目前支持的大概是 112 个,占比 90.3%,同时希姆有一套随机测试,可以测试大质数、融合组合以及一些 pattern 融合组合。
总结
本部分为希姆计算工程师淡孝强现场分享。
这是希姆基于 TVM 搭的 CI,这上面跑了 200 多个模型以及非常多的单元测试。MR 不抢 CI 资源的情况下,提交一个代码需要 40 多分钟。计算量很大,大概挂了 20 多张自研计算卡以及一些 CPU 机器。
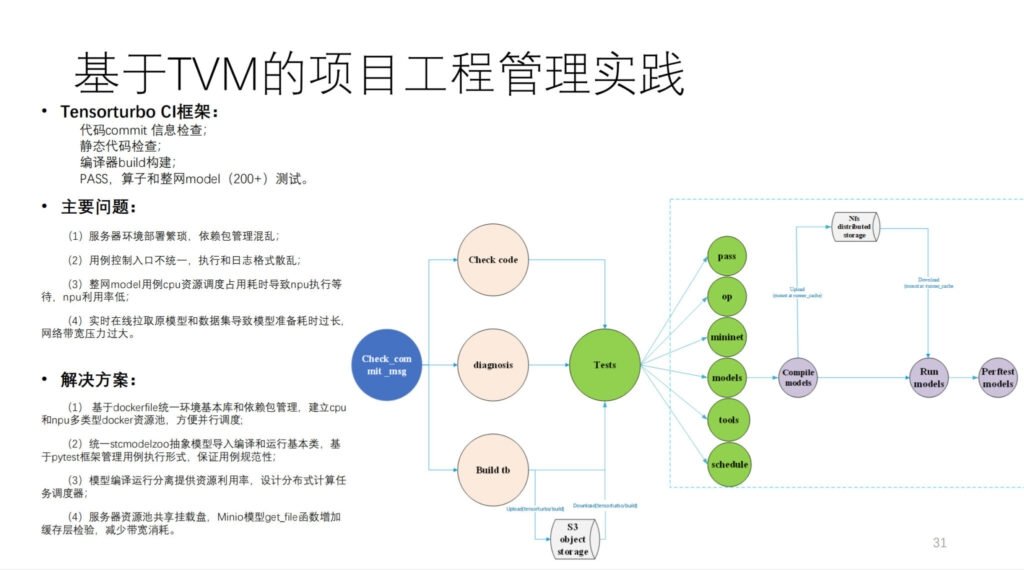
总结,这是希姆的架构图,如下所示:
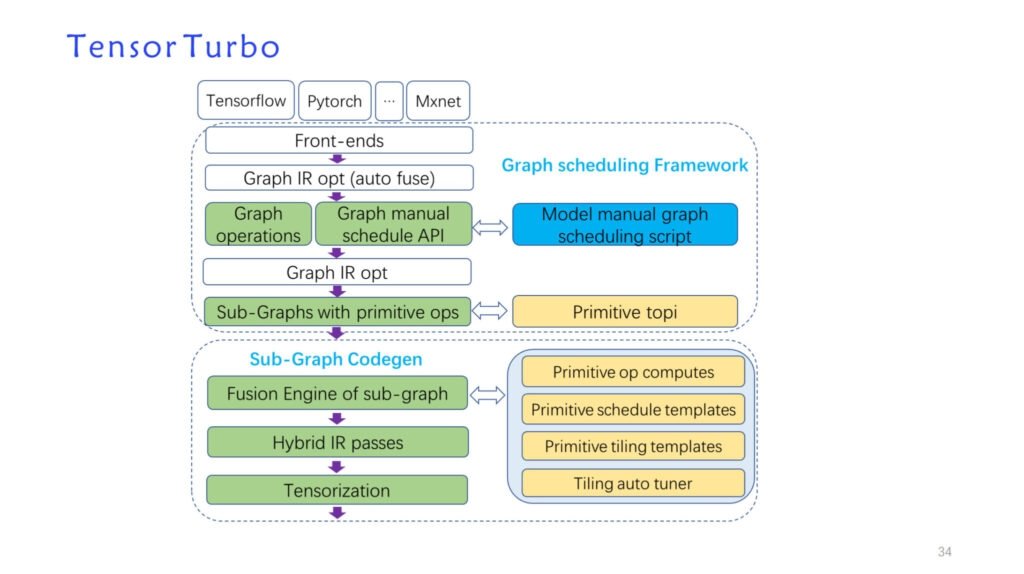
效果来看,性能得到很大提升,另外自动生成与另一个手写模型的团队对标的话,基本上可以达到他们的 90% 以上。

这是希姆代码的情况,左边是 TVM 和自研代码如何管理,TVM 是作为 third_party 里的数据结构来使用,希姆有自己的 source 和 python 的东西,如果我们需要对 TVM 进行更改,就在 patch 文件夹中对 TVM 进行改动。这里有三个原则:
大部分使用自研的 pass,也自研了 Custom module;
patch 会限制少修改 TVM 源代码,能 upstream 就及时 upstream;
定期跟 TVM 社区做同步,更新最新代码到仓库中。
整个代码量也如上图所示。
总结:
我们基于 TVM 端到端支持希姆一代二代芯片;
基于 relay 和 tir 实现所有的编译优化需求;
基于 tir 完成了 100+ 条向量张量指令的自动生成;
基于 TVM 实现了自定义算子方案;
模型一代支持 160+,二代已经使能 20+;
模型性能接近手写极致。
Q&A
Q1:我对融合算子比较感兴趣,它如何跟 TVM 的 tir 结合?
A1:对于右图,同一个算级,第一,如果算子有两个 input 一个 output,那算子形态就有 27 种。第二,各种各样的算子衔接时,scope 有可能是三个之一,所以我们不会假设有固定 pattern。那么如何在 TVM 上实现?首先根据图层调度,决定前后 add 和中间 scope 在哪里,图层是一个非常复杂的过程,输出的结果是决定算子存在于哪个缓存以及可用缓存有多少。有了这个调度的结果,我们在算子层进行自动融合算子生成,比如我们根据 scope 信息进行自动插入数据搬移的操作,完成数据流的构建。
schedule info 里边和 TVM 原生的机制很类似,融合过程中需要考虑每个 member scope 所用的大小,所以这里就是 TVM 原生的东西,我们只是用了一个特别的框架,将其集成到这里,让它自动化。
do schedule 在此基础上,把开发者所需要的 schedule 做出来,可能也会有一些后处理。
Q2:方便透露 CostModel 更多细节吗?cost function 是根据算子层面的 feature 还是根据硬件层面的特性结合设计的?
A1:大思路已经在这了,首先生成一个候选集,生成过程跟 NPL 结构相关,然后会有 剪枝 的过程,考虑指令限制以及后边的优化,多核、double buffer 等,最后有一个 cost function 对其进行排序。
我们知道优化套路本质是如何把数据搬移隐藏在计算中,无非是对操作照此标准进行模拟,最后计算代价。
Q3:除了 TVM 支持的默认融合规则,希姆有没有产生新的融合规则,比如在计算图层结合不同硬件定制的特有融合。
A3:关于融合,实际上有两个层次,第一,buffer,第二,loop 融合。TVM 融合方式实际上是针对后一种。希姆基本沿用你说的 TVM 融合 pattern 的套路,但是做了一些限制。
有关于TVM如何支持NPU的问题到这里就全部解答完毕了,希望对你在人工智能技术方面的研究有所帮助!
首先小编来介绍一下什么是TVM
TVM是TensorFlow.js的一个插件,可以将TensorFlow.js转换为TensorFlow.TVM。TensorFlow.TVM是一个轻量级的版本,具有更快的执行速度和更好的内存管理。它可以减少一些不必要的开销,并提供更好的硬件资源利用率,适合于快速原型设计和迭代开发。同时,它还提供了一种称为“动态绑定”的技术,可以在运行时动态地为每个任务分配适当的GPU资源。
那么在TVM上支持NPU又需要怎么做呢?
DSA 编译器解决的本质问题就是不同的模型需要部署到硬件上,利用各种抽象层级的优化手段,使得模型尽量打满芯片,也就是要压缩气泡。关于怎么去调度,Halide 描述的调度三角形是这个问题的本质。
DSA 编译器要解决的主要问题是什么?首先我们抽象一个 DSA 的架构,如图所示,habana、Ascend 以及 IPU 上都是这个抽象架构的实例化。一般计算核里每个核有向量、标量以及 张量 的计算单元。从指令的操作和数据粒度来看,不少 DSA 可能倾向于使用相对粗粒度的指令,例如二维三维的向量和张量的指令,也有不少硬件使用细粒度的指令,例如一维的 SIMD 和 VLIW。指令间的依赖,有一些是通过显式的接口暴露让软件来控制,有的是硬件自己控制。内存是多级内存,大多是 scratchpad memory。并行有各种粒度和维度的并行,比如 stream 并行、cluster 并行、多核并行以及不同计算部件之间的流水并行。
要支持这样一类架构,从编译器开发者的角度看,是从上述体系 结构 几个方面对 AI 编译器提出不同的需求,这部分后面我们会展开。
从用户的角度看,首先要有一个稳定和泛化的编译器,尽量多的模型或者算子都可以编译成功,另外,用户希望编译器可以提供一个可编程的界面来进行 算法 和算子的自定义,以确保可以独立开展一些关键算法的创新工作。最后,对于类似我们这样的团队或者友商也会关注:怎么用 TVM 构建 AI 编译器,比如怎样管理自研和开源的 TVM 代码,怎么搭建一套高效 CI 等等。这就是我们今天要分享的内容,下面由我的同事来讲编译优化的部分。
希姆计算王成科:DSA 的编译优化流程
本部分为希姆计算工程师王成科现场分享。
首先介绍一下希姆编译实践的整体流程概况。
针对刚才提到的架构特性,我们基于 TVM 数据结构构建了自研的优化 pass 再加上对 TVM 的复用,组成了一个新模式实现:tensorturbo。
我们看到一个比较经典的 DSA 架构,一般会提供一些高效、定制矩阵以及向量层的多核计算核心,拥有一个与之相配合的多层缓存机制,同时也会提供可并行运行的多模组执行单元。相应的我们需要处理以下问题:
对数据计算进行切分、高效绑核以及定制指令的高效向量化;
精细管理有限的片上缓存,在不同的缓存等级上做相应的数据预取;
优化多模组执行的多级流水线,力求得到一个比较好的加速比。
这里红色部分(上图)显示的是整个流程里对 TVM 复用比较高的部分,在 relay 上实现的图层相关比较通用的优化可以直接复用,另外复用程度比较高的是基于 TensorIR 和 custom LLIR 的算子实现部分。像我们刚才提到的跟硬件特性相关的定制优化,则需要更多自研工作。
首先我们来看在图层上自研的一项工作。
关注最左边这张比较典型的计算流图,可以看到从上到下,整体对缓存的占用及对计算的占用都在不断减少,呈现倒金字塔的状态。对于前半部分,模型规模较大时,我们需要着重解决片上缓存驻留的问题;而后半部分,在模型规模比较小的时候,需要处理计算单元利用率较低的问题。如果简单调整模型规模,比如调整 batch size ,较小的 batch size 可以得到较低的 latency ,而相应的 throughput 会有所降低;同样较大的 batch size 会导致 latency 较高,但是有可能提高整体 throughput。
那么我们就可以用图调度来解决这个问题。首先,允许一个比较大的 batch size 输入,保证全程对计算的利用率比较高,然后对整图做一个存储分析,加上切分和调度策略,使得模型的前半部分结果可以更好地缓存在片上,同时实现计算核心利用率较高的结果。实践来看整体可以实现 latency 和 throughput 都表现较好结果(详细可以关注 OSDI 23 希姆文章:Effectively Scheduling Computational Graphs of Deep Neural Networks toward Their Domain-Specific Accelerators,6 月份可获取链接查看)。
下面介绍另外一个软流水的加速工作。
关注右上图,实现了一个比较 native 的四级流水线,但明显不是一个高效的流水线。一般高效的流水线,应该是经过几次迭代后,四个执行单元都可以同步并行起来,那么这需要做一些工作,包括 L1 及 L0 上的切分、L1 上跨层的数据预取以及 L0 层级上的 double buffer 操作。通过这些工作我们可以实现像右下图所展示的,加速比较高的流水线。
由此,也会引入一个新的问题,比如当多个执行单元对缓存的同时读写并发数要高于当前缓存可支持的并发数时,就会产生竞争,这个问题会导致访存效率成倍下降,也就是 Bank Conflict 问题。对此,我们会在编译时静态地对流水线进行模拟,提取冲突对象,结合 cost model 对分配地址进行交换和平移,可以极大地降低该问题的影响。
有了各种 pass 之后,可以以一个简单的 Top-Down 方式把它们组合起来,沿着左图中黑色流程,就得到了一个功能上可行的编译 pipeline。但是实践中发现很多问题,包括思远提到的 pass 与 pass 之间的相互影响、缺少交互逻辑,图层与算子之间缺少沟通逻辑等。可以看到左图中红色部分指示的流程,实践中发现每个路径或者它们的组合都会导致编译失败。如何让其鲁棒性更强?希姆在每个可能失败的 pass 中提供一个反馈路径,在图层和算子之间引入了交互逻辑,进行预分析、 prelower 操作,同时在重点部分引入一些迭代调优机制,最终得到一个泛化性较高且调优能力比较强的整体 pipeline 实现。
我们也留意到,上述工作中对数据结构的改造以及相关设计思想与目前 TVM Unity 设计有较多相似之处,我们也期待 Relax 能够带来更多可能性。
这里展示的是希姆在编译流程中更加细节的 pass,从左到右就是逐层递减的过程,其中红色部分是对 TVM 复用比较高的,越靠近硬件特性部分会有更多的定制 pass。
下面继续对其中的部分模块进行详细介绍。
希姆计算刘飞:DSA 的向量化和张量化
本部分为希姆计算工程师刘飞现场分享。
这个章节将展开介绍希姆向量化和张量化工作。从指令粒度考虑,指令粒度越粗,越接近 Tensor IR 的多层 loop 表达,所以向量化张量化难度越小,相反,指令粒度越细,难度也就越大,我们的 NPU 指令,支持一维/二维/三维的 tensor 数据计算。希姆也考虑过原生 TVM tensorize 过程,但考虑到 Compute Tensorize 对复杂表达能力有限,例如对 if condition 这种复杂表达式做 Tensorized 就比较困难,而且做 Tensorized 向量化后,无法 schedule。
另外当时 TensorIR Tensorize 在开发当中,不能满足开发需求,所以希姆提供了自己的一套指令向量化流程,我们称之为指令发射。这套流程下我们支持了大概 120 条 Tensor 指令,包括各种维度的指令等。
我们的指令流程大概分为三个模块:
发射前的优化处理。对循环轴的变换,为指令发射提供更多的发射条件和可能;
指令发射模块。分析循环的结果和信息,选择一个最优的指令生成方式;
指令发射后的模块。对指定发射处理失败之后处理,保证在 CPU 上正确执行。
下面是指令发射前的优化和处理模块,都是由一组优化 pass 组成,其中 IfPromotion 是把阻碍循环轴发射的 if 语句尽量外提,PreProcess 是把没有对应指令的 operator 做拆分处理,LoopShift 是对循环轴边界为 归一化 ,LoopCallapse 是对连续的循环轴作尽可能的合并,LoopPartition 是做 if 相关的循环轴拆分,还有 LoopFission 是对循环内多个 store 语句的分裂。
从这个例子可以看到,起初 IR 是不能发射任何指令的,通过优化后,最后可以发射两条 Tensor 指令且所有的循环轴都能够发射指令。
再就是指令发射模块。首先,指令发射模块会循环分析循环中的结构,从中获取 Optype、dtype、bufferAcess 等信息,有这些信息之后,指令识别会识别出来循环轴可能会发射哪几种指令。因为一种 IR 结构可能对应多种 NPU 指令,所以我们会把所有可能发射的指令都识别出来,由 VectorEngine 搜索引擎去根据指令的 alignment、reshape 等一系列信息去搜索每种指令发射的可能性,最后再由 CostModel 做计算,找到最优发射形式进行发射。
最后就是指令发射后处理模块。主要是对指令发射失败的 tir 做处理,保证其能在 CPU 上正确运行。还有一些特殊指令,希姆需要在算法前端打一些标记,指令发射模块通过这些标记加上自己的 IR 分析,正确地发射相应的指令。
以上是希姆整个 DSA 张量化和向量化的流程,我们也在一些方向上做了探索,比如微内核的方案,也是最近讨论比较热烈的方向。它的基本思想是把一个计算过程分成两层,一层用组合微内核的形式去拼接,另一种用搜索的方式去寻找,最终把两层的结果做拼接,选择一个最优结果。这样其优势是充分利用硬件资源的同时,降低搜索的复杂度,提高搜索效率。
希姆也在微内核上做了相关探索,但考虑到微内核方案与现在的解决方案相比,并没有在性能等方面有较大提升,所以目前希姆在微内核方向还属于探索阶段。
希姆计算袁晟:DSA 的自定义算子
本部分为希姆计算工程师袁晟现场分享。
首先,我们知道算子开发目前碰到了四个大问题:
需要支持的神经网络算子很多,进行归类后基础算子有 100 多个;
由于硬件架构不停迭代,相应指令以及算子参与的逻辑都需要进行变更;
性能考虑。算子融合 (local memory, share memory) 以及我前边提到的图算信息传递(切分等);
算子需要开放给用户,用户只能进入软件进行自定义算子。
我主要分成了以下三个方面介绍。首先是图算子,图算子是基于 relay api,把它裁剪成基础的语言算子。
以下图为例:
第二是元算子,所谓的元算子是基于 TVM Topi 用 compute/schedule 描述算子算法逻辑和循环变换相关逻辑。我们在开发算子时,会发现很多算子的 schedule 是可以复用的,基于这种情况下,希姆提供了一套类似 schedule 的模板。现在,我们把算子分成很多类,基于这些类,新的算子就会大量复用 schedule 模板。
接下来是一个比较复杂的算子,基于 NPU 的情况下,大家会发现 topk、nms 等带控制流的算法,带很多标量计算,目前用 compute/schedule 很难描述,为解决这个问题,希姆提供一个类似 library 库。相当于在 library 库先编译复杂的逻辑,然后通过跟 IR Builder 结合的方式,把整个算子的逻辑输出。
接下来是算子的切分。对于 NPU,相对 GPU 和 CPU 情况下,TVM 每条指令都会操作连续内存块,同时会有 memory size 限制。同时,在这种情况下,搜索空间不大。基于这些问题,希姆提供了解决办法,首先,会有一个候选集,把可行的解题放到候选集里,其次,对可行性进行解释,主要考虑性能要求以及 NPU 指令限制,最后,会引入 cost function,其中会考虑算子特征以及可能用到的计算单元特征。
再接下来对算子开发比较有挑战性的就是融合算子。目前面临两个爆炸性问题,第一不知道如何将自己的算子和其他算子组合,第二个可以看到 NPU 里有很多 memory 层级,出现爆炸式 memory 层级的融合。希姆 LLB 会有 shared memory 和 local memory 等融合的组合,基于这种情况下,我们也提供一个自动生成框架,先根据图层给的调度信息,插入数据搬移操作,再根据 schedule 里 master op 和 salve op 提炼 schedule info,最后根据当前指令的限制等问题做一个后处理。
最后主要展示希姆支持的算子。ONNX 算子大概是 124 个,目前支持的大概是 112 个,占比 90.3%,同时希姆有一套随机测试,可以测试大质数、融合组合以及一些 pattern 融合组合。
总结
本部分为希姆计算工程师淡孝强现场分享。
这是希姆基于 TVM 搭的 CI,这上面跑了 200 多个模型以及非常多的单元测试。MR 不抢 CI 资源的情况下,提交一个代码需要 40 多分钟。计算量很大,大概挂了 20 多张自研计算卡以及一些 CPU 机器。
总结,这是希姆的架构图,如下所示:
效果来看,性能得到很大提升,另外自动生成与另一个手写模型的团队对标的话,基本上可以达到他们的 90% 以上。
这是希姆代码的情况,左边是 TVM 和自研代码如何管理,TVM 是作为 third_party 里的数据结构来使用,希姆有自己的 source 和 python 的东西,如果我们需要对 TVM 进行更改,就在 patch 文件夹中对 TVM 进行改动。这里有三个原则:
大部分使用自研的 pass,也自研了 Custom module;
patch 会限制少修改 TVM 源代码,能 upstream 就及时 upstream;
定期跟 TVM 社区做同步,更新最新代码到仓库中。
整个代码量也如上图所示。
总结:
我们基于 TVM 端到端支持希姆一代二代芯片;
基于 relay 和 tir 实现所有的编译优化需求;
基于 tir 完成了 100+ 条向量张量指令的自动生成;
基于 TVM 实现了自定义算子方案;
模型一代支持 160+,二代已经使能 20+;
模型性能接近手写极致。
Q&A
Q1:我对融合算子比较感兴趣,它如何跟 TVM 的 tir 结合?
A1:对于右图,同一个算级,第一,如果算子有两个 input 一个 output,那算子形态就有 27 种。第二,各种各样的算子衔接时,scope 有可能是三个之一,所以我们不会假设有固定 pattern。那么如何在 TVM 上实现?首先根据图层调度,决定前后 add 和中间 scope 在哪里,图层是一个非常复杂的过程,输出的结果是决定算子存在于哪个缓存以及可用缓存有多少。有了这个调度的结果,我们在算子层进行自动融合算子生成,比如我们根据 scope 信息进行自动插入数据搬移的操作,完成数据流的构建。
schedule info 里边和 TVM 原生的机制很类似,融合过程中需要考虑每个 member scope 所用的大小,所以这里就是 TVM 原生的东西,我们只是用了一个特别的框架,将其集成到这里,让它自动化。
do schedule 在此基础上,把开发者所需要的 schedule 做出来,可能也会有一些后处理。
Q2:方便透露 CostModel 更多细节吗?cost function 是根据算子层面的 feature 还是根据硬件层面的特性结合设计的?
A1:大思路已经在这了,首先生成一个候选集,生成过程跟 NPL 结构相关,然后会有 剪枝 的过程,考虑指令限制以及后边的优化,多核、double buffer 等,最后有一个 cost function 对其进行排序。
我们知道优化套路本质是如何把数据搬移隐藏在计算中,无非是对操作照此标准进行模拟,最后计算代价。
Q3:除了 TVM 支持的默认融合规则,希姆有没有产生新的融合规则,比如在计算图层结合不同硬件定制的特有融合。
A3:关于融合,实际上有两个层次,第一,buffer,第二,loop 融合。TVM 融合方式实际上是针对后一种。希姆基本沿用你说的 TVM 融合 pattern 的套路,但是做了一些限制。
有关于TVM如何支持NPU的问题到这里就全部解答完毕了,希望对你在人工智能技术方面的研究有所帮助!