问答
cosyvoice生成的音频断句不自然怎么办 断句不自然解决方法
- 2025-01-18
- 朴老师
- AI吧
哈喽大家好,这里是AI吧教学日记的朴老师,cosyvoice作为当前效果非常不错的克隆软件,相信大家都已经尝试过了吧,是不是轻松解决了配音难的烦恼,成为了你离不开的生产工具呢?现在朴老师根据在使用cosyvoice生成音频时所遇到的断句不自然的情况进行分析解答,帮助大家生成更加自然的声音。
不自然原因:
模型数据不足:没有足够多的数据支撑,标点断句识别不精准,导致断句错乱不自然,该问题多出现在V1.X版本,V2.X版本基本不会显现此类问题。
样音断句不标准:人说话时因为肺活量和需要过脑思考等因素,会出现正常的断句不自然等情况;AI会将这些视为参考音频的特征,克隆的时候会直接将其赋予在生成的音频当中,从而导致生成内容断句不自然。
解决方法:
1、更换最新版软件,最新的2.0以上版本模型数据采样更多,模型也更加成熟,即便是进行长文本生成,也很少出现断句不自然的情况。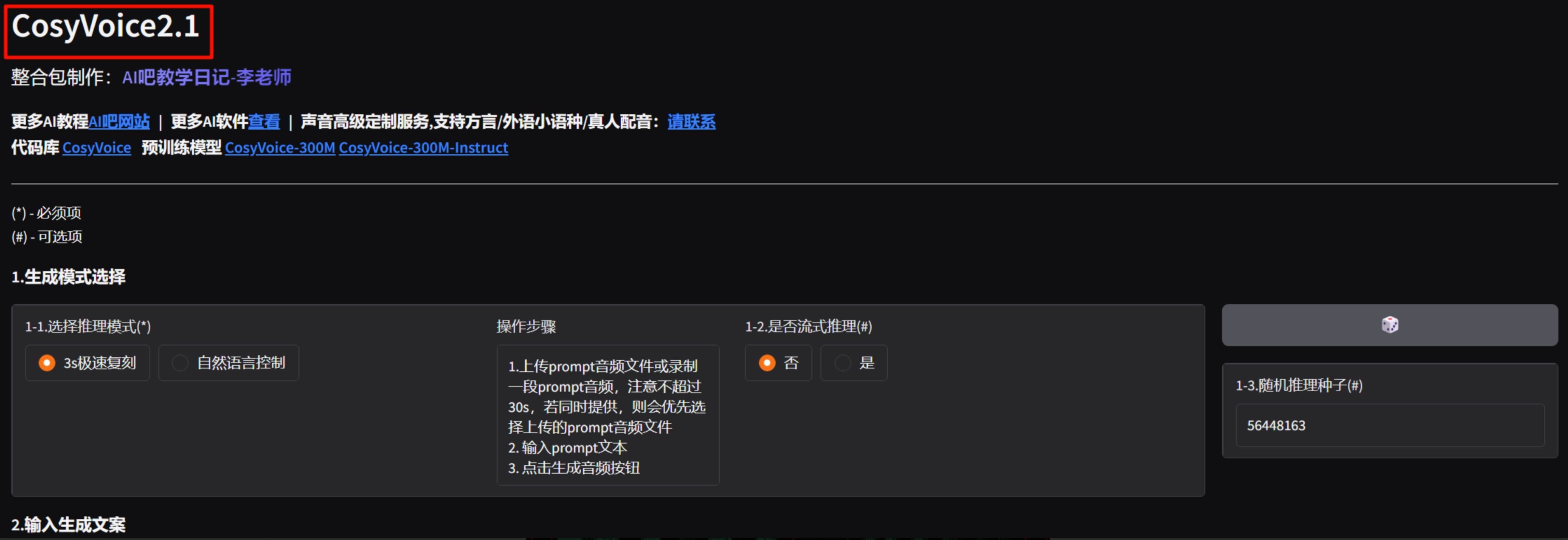
2、将参考音频更换为断句[更加自然清晰]的样本音频,或使用剪辑工具[剪映]或[Adobe Audition],将样音留白的间隔音频进行裁剪,只保留克隆目标的声音,将数据集中起来,确保给到cosyvoice的音频数据全是有用的数据。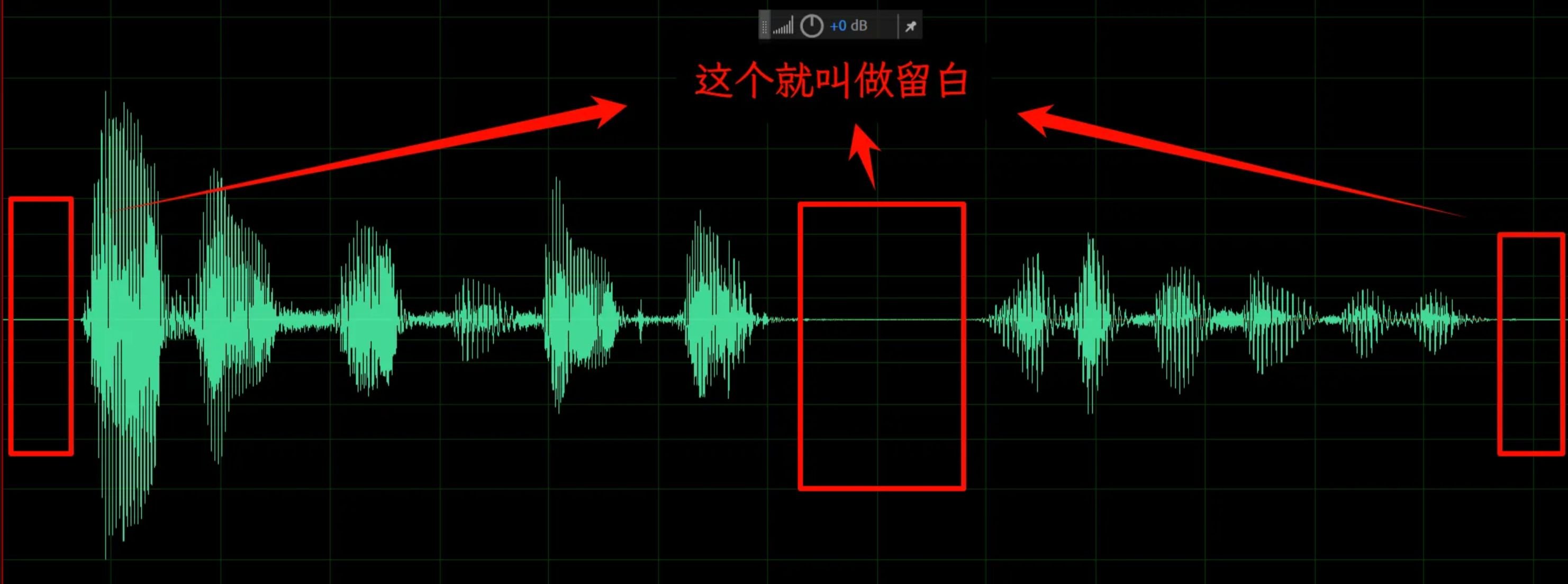
3、如果使用的是1.0版本,可将所有标点符号进行统一修改,全部更改成句号,或在需要断句的地方加入句号,1.0版本识别断句以句号为主,全部修改后不仅能极大程度上改善断句不自然的情况,还能解决整体语速过快的问题。
4、将断句错误的句子单独进行生成,生成断句不满意,可以点击[骰子]后重新生成,骰子会将种子随机化,生成不同语气的音频,需要反复抽卡,直到满意为止。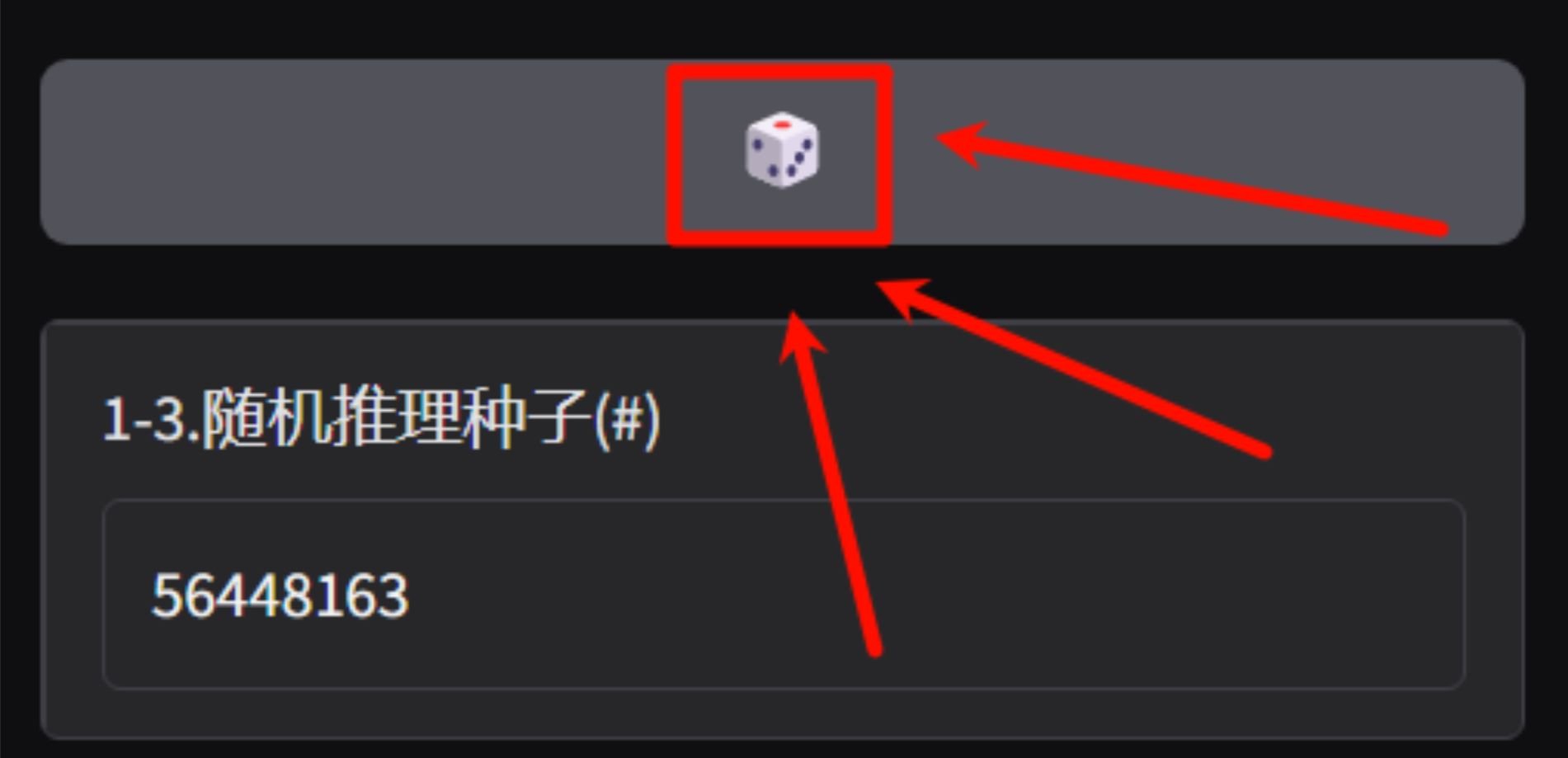
通过这四种方法,在生成时可以有效避免断句不自然的情况,能够更加高效的克隆出音频,若在后续使用中还遇到其他关于cosyvoice的问题,关注AI吧,我们将持续为大家带来教学内容。